
[nodejs] crawling-naver webtoon-4
request package
request package 소개
크롤링은 인터넷에 있는 data를 가져온다. 동영상,음악,사진과 같은 multimedia한 데이터, 문서에 있는 text data도 통신을 해서 가져온다. url만 있다면 가져올 수 있다. 보통 multimedia한 data들은 url이 html문서안에 숨어 있기때문에 찾는 과정이 필요하지만, 이것은 별도의 package로 처리하고 여기서는 request package를 사용할 수 밖에 없는 이유에 대해서 말할려고 한다. 어떤 data라 할지라도 http통신을 해야만 한다. request package는 url을 제공하면 url을 다운받는다. 따라서 크롤링을 한다고 하면 100% 사용하는 package다. 하지만 불행히도 이 module은 2020년에 depreciated되었다. 하지만 그냥 쓰기로 한다.
request package 사용법
webapp을 사용하는 경우 node project를 만들어서 사용하는게 편하다. node project를 만들자.
[step1] github에 project를 만든다.
mini-crawling이라는 project를 만들었다. local에 clone한다.
[step2] nvm use v18.17.0
최신 node를 설정한다.
[step3] npm init
package.json이 만들어진다.
[step4] npm install –save request
request package를 local에 설치한다.
[step5] touch index.html index.js
index.html과 index.js를 만든다.
[step6] index.js에 코드를 작성한다.
request를 load하고 사용하는 code를 작성한다.
let request = require('request')
request('http://www.google.com', function(error, response,body){
console.log('error:',error);
console.log('statuscode:', response && response.statusCode);
console.log('body:', body);
});
[step7] node index.js
node로 js파일을 실행한다. node는 python같은 interpreter라고 생각하면 된다.
webtoon 문서 가져오기
webtoon을 하나 선택해서 만화가 있는 page의 url을 request에 넣고 문서를 가져오는지 확인한다. 얼짱시대라는 웹툰이다. https://comic.naver.com/webtoon/detail?titleId=813335&no=1 이 주소를 넣었다.
request의 callback function-response와 body
request의 callback함수를 보면, response와 body가 있다. response는 응답헤더도 포함하고 요청에 대한 문서가 body에 포함되어 있다. request callback함수에 body가 별도로 있는데, 이것은 url요청에 대한 응답문서를 보내준다. 차이점이 있다. response의 header에 포함된 body는 사람이 알아보기 힘들지만, body는 사람이 알아보기 쉽게 되어 있다는 것이다.
html 문서 파싱
request를 사용해서 html문서를 가져왔지만, 실제 우리가 원하는 resource의 url은 html문서내에 숨어있다. 따라서, html문서 내에서 img태그를 찾을 수 있어야 한다.
개발자 도구에서 만화 이미지 찾기
우리의 목표는 웹툰의 image를 찾는 것이다. 개발자도구에서 html문서를 볼수 있다. 그리고 JQuery를 사용해서 img태그를 배열로 가져올 수 있다. 이렇게 원하는 것을 가져올 수 있어야 한다. 다음 그림을 보자.
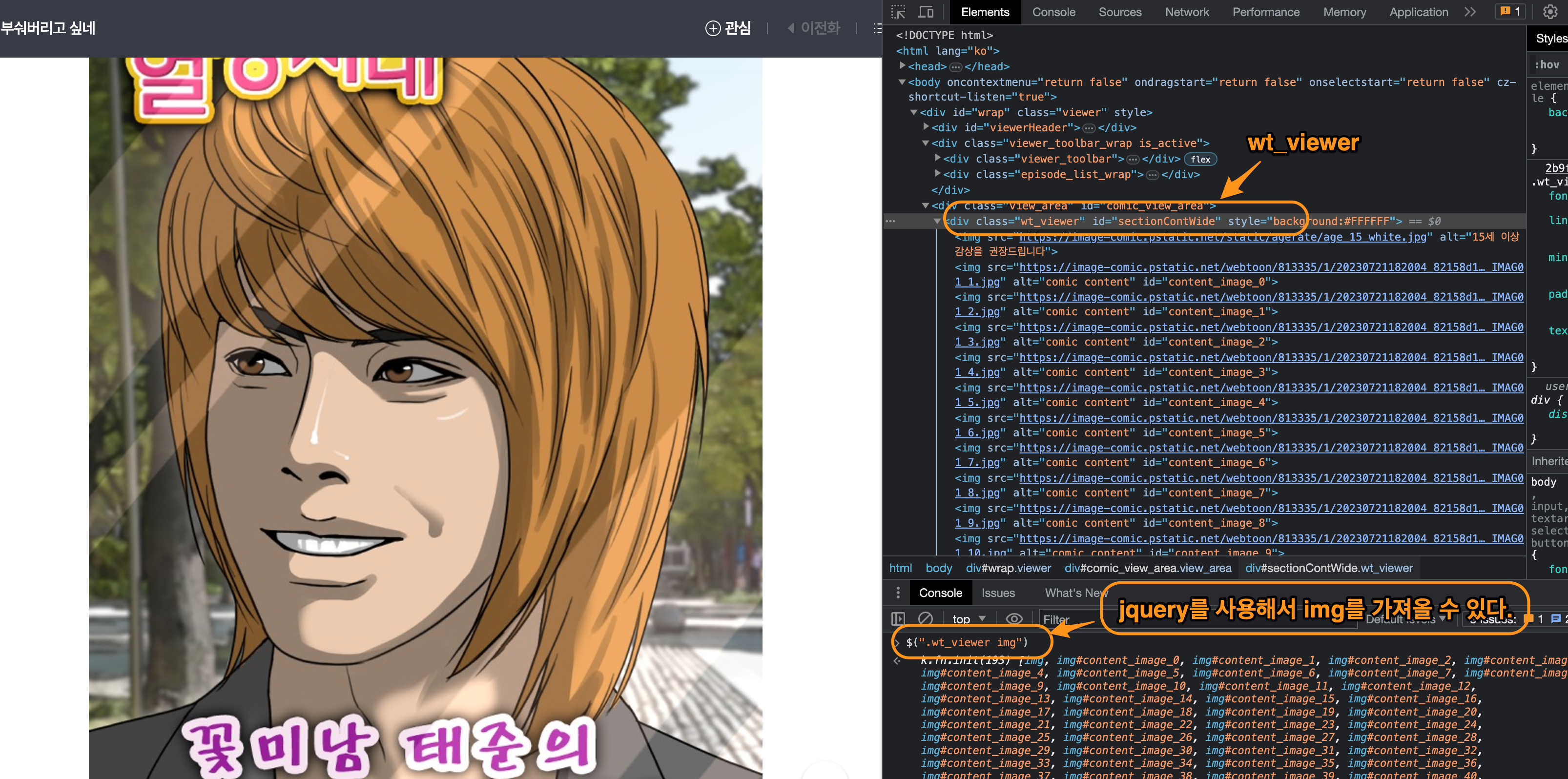
Figure 1: jquery
아마도 web toon image viewer를 뜻하는 거 같은데, class명으로 선택해서 img를 찾을수가 있다.
$(".wt_viewer img")
jquery를 지원하지 않는 경우도 있다고 한다. 이럴때는 query selector를 사용할 수 있다.
document.querySelector(".wt_viewer");
하지만, jquery를 사용하는게 나중에 사용될 package때문에 더 선호된다고 한다. cheerio라는 모듈을 사용하게 될텐데, 거기서 jquery를 사용하는 모양이다. 그래서 jquery를 어떻게든 사용하게 만들어야 한다고 한다. 개발자도구에의 console에서 jquery를 사용하게 하는건 간단하다. jquery source code를 구글링해서 얻어온 후에 개발자 도구 console창에서 복사 붙여넣기로 넣은 후 enter를 누르면 jquery를 사용할 수 있다고 한다. 이제 jquery를 사용할 수 있게 되었다. 그런데 한가지 알아야 할 게 있다. jquery로 검색할때, 다음과 같은 html태그가 있다고 하자.

Figure 2: html code
selector인 .wt_viewer를 접근할때 아래와 같은 code를 사용하면 <div class=‘wt_viewer’ …> 가 return할 꺼 같지만, jquery object만 return 받는다. 아래를 보자.
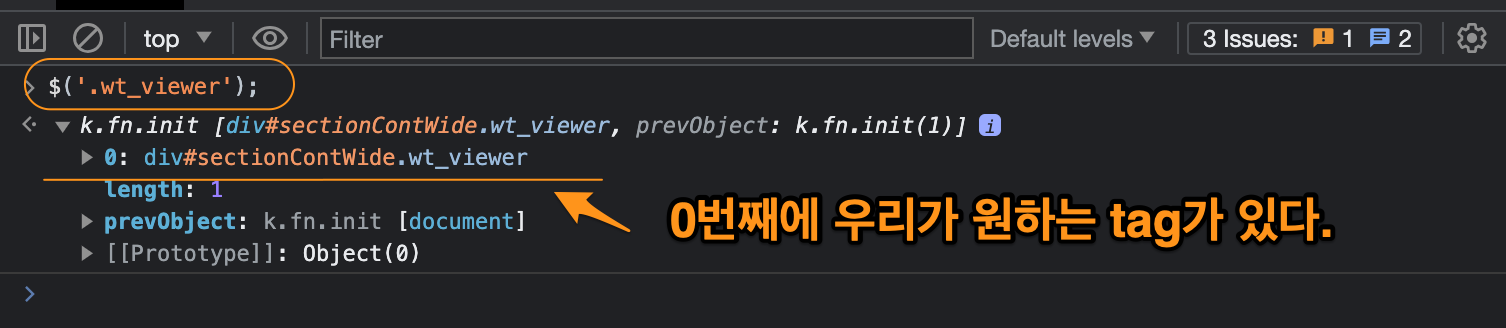
Figure 3: html code
0번째에 우리가 원하는 tag가 있다. 그래서 아래와 같이 해줘야 한다.
$('.wt_viewer')[0]
이렇게 해주면, div태그가 포함하는 img태그를 모두 얻을 수 있다. 하지만, 각각의 img태그를 접근하는건 아니다. img태그를 포함하는 div태그에 접근한 것일뿐이다. img태그를 접근하는건 간단히
$('.wt_viewer img')
위와 같이 하면 접근할 수 있다.
정리
여기서는 request라는 module을 사용하면 html문서를 가져올 수 있고, html문서에 숨겨진 resources들을 찾아서 가져올 수 있다는 가능성을 개발자 도구에서 엿봤다. 다음에는 crawling에서 cheerio를 사용해서 우리가 진짜 원하는 resource를 가져오는 것을 살펴볼 것이다.