
[python] grammar in one shot
목적
python으로 된 code를 보고 이해하는 게 목적이다. 우선 python의 언어적 특징을 알아보자.
about python
python의 특징
python으로 작성된 code를 이해하려면 python에 관해 알아야 할게 있다. python의 구성과 oop다. python은 c로 작성된 부분과 python으로 작성된 library로 나눠진다. python의 근간을 이루는 grammar, parser, class, data type은 c로 작성되었다. standard library도 c로 작성되었다. 나머지 library는 python으로 작성되어 있다. python은 oop language다. 모든 것이 객체다. 그리고 python은 엄청난 package가 제공된다. package를 설치하고 사용만 할 줄 알면 모든 것을 할 수 있다는 얘기가 있다. 좀 더 python이 가진 언어적 특징은 아래를 참고하자. 프로그래밍의 역사 를 보면 내가 생각하는 program에 대한 설명이 나와 있다.
python의 종류
- cpython: 일반적인 python이다. c로 구현되어 있다.
- pypy: jit compiler를 사용해서 cpython보다 빠르다. 코딩 테스트할때 많이 사용한다. pandas, sklearn,matplotlib을 지원하지 않아서 data분석에 사용되지 않는다.
- ipython: jupyter나 colab에서 사용하는 server client기반의 python이다.
- mypy: typ system.
python preparation
python 코드를 읽거나 작성하기전 알아야 할 사항이다. environment와
package 설치에 관한 부분이다. env는 conda를 사용 하고 package설치는 pip와 conda 를 사용한다.
python environment
create env
conda create -n test-env python=3.7.0
conda create -n test-env python=3.7.0 anaconda
shell에서 위 명령을 실행하면 test-env라는 환경을 아래 폴더 아래 만든다. anaconda를 덧붙이면 anaconda의 기본 package들이 설치된다고 한다.
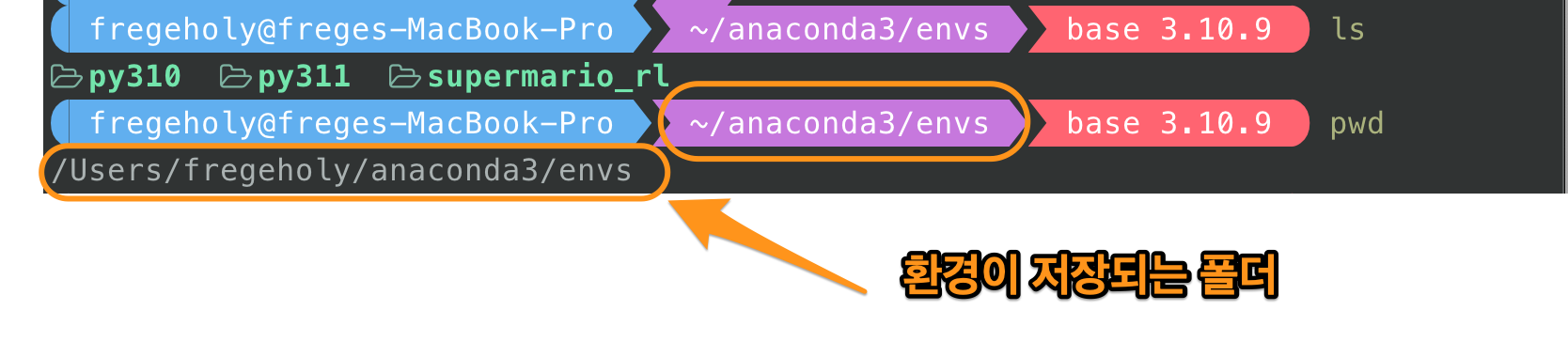
Figure 1: conda env
list envs
conda env list
shell에서 위 명령을 실행하면 env들을 보여준다.

Figure 2: conda env list
activate env
conda activate py310
shell에서 위 명령을 실행하면 py310이 activate된다.
remove env
conda env remove -n py310
env를 삭제하는 명령이다.
python package
install package
conda install numpy
conda로 numpy package를 설치하면,
~/anaconda3/envs/py310/lib/python3.10/site-packages 에 설치된다. package들이
설치되는 위치다.
pip install numpy
pip로 설치해도 ~/anaconda3/envs/py310/lib/python3.10/site-packages
에 설치된다. pip와 conda는 동일한 위치에 설치한다. 그러나 pip와
conda가 설치하는 package는 같은 package도 아니고 같은 곳에서 package를
가져오지도 않는다. pip가 가져오는 package는 순수하게 python으로 만든
package고, conda가 가지고 오는 package는 다양한 언어로 만든
package라서 다른 package다. pip의 package는 python으로 만든 최신
package가 있고, conda의 package는 system에 좀더 안정화된 package다.
list installed packages
conda list
conda와 pip를 같이 사용하면 중복으로 package가 설치된다. conda list는
~/anaconda3/envs/py310/lib/python3.10/site-packages 에 설치된
package들이 모두 출력된다. 여기에는 pip와 conda가 설치한 package들이
모두 있다. 만일 package가 없다면,
conda install [package]
conda로 package를 설정한다. 그런데 conda에는 없고 pip에만 있는 package는 pip로 설치해야 한다. 이때 –upgrade를 붙이자.
pip install --upgrade [package]
package를 설치할때 conda와 pip 어떤걸 사용할 지 고민하지 말자. 편한걸로 아무거나 사용하면 된다. 섞어서 사용해도 된다. 다만 pip는 –upgrade를 사용해서 설치하자. pip는 최신 버전을 설치하지 않기 때문이다. 반면 conda는 default로 최신 버전을 설치한다.
python interpreter 생성과 초기화
in the beginning
$python
shell에서 python을 실행하면 python interpreter가 생성된다. interpreter가 생성하면서 다음과 같은 것을 하게 된다.
(1) symbol table을 만든다.
interpreter가 실행되면, symbol table을 만든다. locals()와 globals()를 만드는데, module을 load할때 module의 symbol들을 local과 global symbol table에 저장한다. local과 global의 차이가 무엇인가?
import numpy
a = 3
def test():
b = 3
print(" this is b {}".format(b))
- import로 module을 가져오면 module에서 정의된것은 모두 globals에 등록되어서 사용할 수 있다. 그리고 현재의 main module에 있는 a, test도 globals에 등록된다.반면에 locals는 b가 등록된다.
(2) loader를 loading한다.
_frozen_importlib_external.SourceFileLoader라는 loader가 있다. python의 내장 모듈과 standard library module을 load할 수 있는 loader다. python에서는 module마다 loader를 설정할 수 있다고 한다. 즉 customization loader가 있을 수 있다. loader를 load하고 symbol table에 등록한다.
(3) loading standard library module
sourceFileLoader로 math,os,sys와 같은 module을 loading한다. 그런 다음에 os가 제공한 정보로 설정된다. 아래는 그 예다.
import sys
# 명령행 인자 확인
if len(sys.argv) > 1:
# 첫 번째 인자는 스크립트 이름이므로 두 번째 인자부터 확인합니다.
for arg in sys.argv[1:]:
print("명령행 인자:", arg)
# 실행 환경과 관련된 설정 확인
print("실행 모드:", sys.executable) # 인터프리터 실행 경로
print("환경 변수:", sys.path) # 모듈 검색 경로
print("플랫폼:", sys.platform) # 운영 체제 플랫폼 정보
실행 모드: /opt/homebrew/anaconda3/bin/python
환경 변수: ['', '/opt/homebrew/anaconda3/lib/python311.zip', '/opt/homebrew/anaconda3/lib/python3.11', '/opt/homebrew/anaconda3/lib/python3.11/lib-dynload', '/opt/homebrew/anaconda3/lib/python3.11/site-packages', '/opt/homebrew/anaconda3/lib/python3.11/site-packages/aeosa']
플랫폼: darwin
(4) loading built-in function
두번째로 built-in module을 load하는데, built-in function들이 있다. 그리고 exception 관련 class를 loading한다.
(5) loading module로부터 symbol table에 저장되는 것들.
interpreter는 symbol table을 만들고, loader를 load하고, loader로 부터 module을 load한다. load를 하면 ascii나 byte로 된 module(파일)을 읽고 객체들을 메모리에 생성하게 되는데, 생성된 객체들의 symbol들을 symbol table에 저장한다. symbol table에는 미리 정해진 요소들이 있다. 아래에서 보겠지만, ‘name’,’package’,’doc‘등등의 요소들은 미리 python interpreter가 생성될때 정해진 요소들이다. 이런 요소들은 인자로 전해진 code를 읽고서, symbol table에 저장되게 된다. python interpreter가 초기화되는 과정에서는 아래와 같은 요소들이 name만 있는 상태고 실제 value가 저장되는것은 stdin이나 python file이 인자로 전해져서 code를 evaluate하면서 설정되는 것이다. 아래는 미리 정해진 symbol table의 요소들이다. locals()는 local symbol table이고 globals()는 global(전역) symbol table이다.
print(locals())
print(globals())
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '<stdin>', '__cached__': None}
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '<stdin>', '__cached__': None}
-
__name__ symbol
python interpreter가 초기화되는 과정에서 symbol table에 미리 만들어놓은 symbol중에 하나다. ‘name‘은 현재 실행되고 있는 모듈의 이름을 나타낸다. python interpreter는 미리 ‘name‘이라는 요소를 symbol table에 갖고 있다고 했다. module이란건 파일의 이름이다. 처음에는 None이지만, 인자로 stdin처럼 script가 전달되거나 파일이름이 전달되면, 실행되는 module의 이름이 설정된다. 그런데 직접전달 되는 경우, ‘name‘은 무조건 모두 ‘main’ 이라는 값을 갖게 된다. 아래의 예도 모두 stdin으로 전달되는 script라서 main이름을 갖는다.
print('hello') print(locals())hello {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '<stdin>', '__cached__': None}다음 예를 보자. a.py와 b.py 두개의 file이 있다고 하자. 아래는 a.py다.
print("this is a.py") print(__name__)this is a.py __main__b.py는 아래와 같다.
import a print(" this is b.py") print(__name__)$ python b.pypython b.py를 하면, 첫번째 문장 import a를 실행하는데, 이것은 a module을 evaluate한다. 그러면 “this is a.py” 가 출력되고 __name__에 해당하는 a가 출력된다. 그리고 main module로 넘어와서 “this is b.py"가 출력되고 b가 출력된다.
다음 예를 보자. 2개의 file이 있다. a.py와 b.py이다. a.py는 함수가 정의 되어 있고, b.py에서 a.py의 함수를 호출한다.
def test_print(): print("test.py)아래는 b.py이다.
import a a.test_print()여기서 python b.py를 실행해보자.
$ python b.pymain module인 b.py에서는 import a를 호출한다. a module을 실행하지만, 여기서 ‘name‘은 a이고, test_print라는 symbol을 symbol table에 저장한다. 그리고 main module에서는 a module의 함수를 호출하기 때문에 ‘name‘은 a이다.
- ’name‘의 사용: ‘name‘값이 python의 인자로 지정되면
‘main‘이란 이름을 갖게 된다. 이것은 module의 entry point를
지정할 수 있게 해준다. python interpreter의 symbol table에
‘name‘이 main으로 지정되기 때문에
if __name__ =‘main’:= 를 사용해서 module마다 entry point를 설정하는 것이다. 일반적으로 python으로 program을 작성할때 module로 작성한다. 각 module에는 class나 function을 define할 뿐이다. 다른 module에서 import하면, 정의된 function, class를 사용 한다. entry point를 지정하지 않으면, module들이 python의 인자로 주어져도, 아무것도 실행하지 않는다. entry point가 없기 때문이다. module에 entry point를 정의할때 사용하는게 symbol table에 저장된 ‘name‘의 값인 ‘main‘을 사용하는 것이다.
- ’name‘의 사용: ‘name‘값이 python의 인자로 지정되면
‘main‘이란 이름을 갖게 된다. 이것은 module의 entry point를
지정할 수 있게 해준다. python interpreter의 symbol table에
‘name‘이 main으로 지정되기 때문에
-
‘doc’ symbol
python interpreter에 초기 symbol table에는 ‘doc‘라는 symbol이 할당되어 있다. 이 symbol에는 docstring이 저장된다. python에서는 module,class,function에 해당 기능을 설명하는 docstring을 기술할수 있다. 이것은 pydoc을 통해서 문서를 만들때 유용 하게 쓰인다. module의 doc string은 string literal로 작성되기 때문에 symbol table에 저장하기 위해서 ‘doc‘라는 key값으로 저장한다. 아래를 보자.
''' this is doc string ''' print(locals()){'__name__': '__main__', '__doc__': ' this is doc string ', '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '<stdin>', '__cached__': None}
-
‘package’ symbol
‘package‘도 원래 python interpreter가 처음 실행될때 만드는 symbol table에 미리 setting된 symbol중 하나다. ‘name’ 현재 동작하는 module의 이름을 나타내듯이, ‘package‘는 현재 실행되고 있는 module의 package를 나타낸다. module은 python file이다. 반면 package는 module들을 포함하는 folder라고 볼 수 있다. 아무 folder나 package가 되는 것은 아니고, init.py가 포함된 폴더다. init.py에는 package에 포함되어 있는 module들이 공유하는 함수나 변수를 기술하거나 초기화하는 작업을 한다. 여튼 a.py가 아래와 같이 있다고 하자.
print('hi') print(__package__)hi None$ python a.py여기서 ‘package‘는 none이다. main module인 a.py에 package는 없다. 왜냐면 entry point이기 때문이다. 그러면 package가 있는 module을 사용한 예제를 만들어보자.
submodule/a.py가 아래와 같다고 하자.
print("__package__ = {}".format(__package__)b.py는 다음과 같다.
import submodule.a print("__package__ is ", __package__)$ python b.pyb.py를 실행하면, import submodule.a를 실행한다. 따라서 submodule이 출력되게 된다. 그리고 다시 main module로 와서 none을 출력하게 된다.
- __package__의 사용: 상대 경로를 사용할 수 있게 한다. 예를 들어보자.
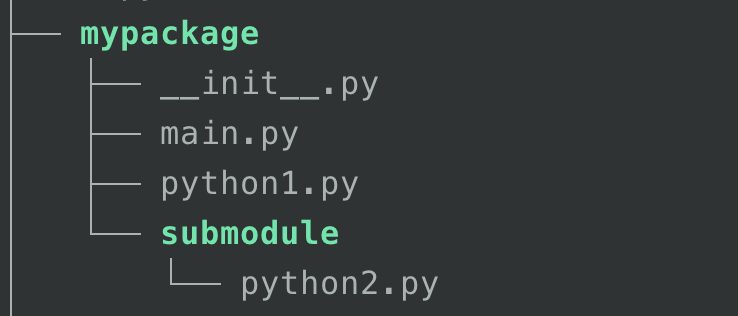
Figure 3: tree1
위와 같은 구조에서 main.py는 다음과 같다고 하자.
from mypackage.submodule.python2 import printstr printstr()$ python main.pymain.py를 실행하면 from mypackage.submodule.python2 import printstr를 실행한다. 즉, mypackage.submodule.python2.py를 실행한다. 따라서, ‘package‘의 값은 “mypackage.submodule"로 설정된다. 여기서 python2.py 파일을 보자.
from ..python1 import some_functionfrom에서 상대경로를 나타내는 ..이 있다. 상대 경로를 사용할 수 있는 이유는 “package” 값이 symbol table에 있기 때문이다. 위에서 “mypackage.submodule"이란 값이 ‘package‘값이기 때문에, 그에 따른 상대경로를 지정할 수 있다.
-
‘spec’:
spec은 loader의 정보를
-
‘annotations’:
요약
python code를 해석하고,code를 작성하기 위해선, 내가 python interpreter가 되어야 한다. python interpreter가 되어야 code를 해석할 수 있다. 인자로 주어진 code를 해석하기에 앞서서, python interpreter는 사전 준비를 한다. symbol table을 만들고, loader를 load하고, loader를 사용해서 standard library를 load하고, built-in function을 load한다. load된 모든 module의 symbol들은 symbol table에 저장되어 있다. 그래서 code를 해석할때, 해당 symbol에 대한 처리를 할수 있는 것이다. 여튼 그런 다음 argument에 대한 처리를 하게 된다. 우리도 python code를 보기전에 python interpreter가 되어보는건 어떨까?
built-in module
built-in functions
python interpreter가 load된 다음 built-in function을 load해서 symbol table에 저장한다.
print(globals())
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '<stdin>', '__cached__': None}
'__builtins__': <module 'builtins' (built-in)>}
built-in module에 built-in function들과 exception, warning들이 포함되어 있다.
built-in exceptions
python interpreter가 load된 다음 built-in exception을 load한다.
standard libraries
python interpreter가 load된 다음 standard library를 load해서 symbol table에 저장한다.
os
sys
math
요약
$ python
shell에서 python을 실행하면 python interpreter가 메모리에 만들어진다. 초기화 과정을 거치면서 python에 무언가 할 수 있는 능력이 생긴다.
python interpreter first input
python interpreter의 입력
string의 입력과 출력
python interpreter로 program을 실행시킨다. program은 python interpreter의 입력으로 주어진다. 입력은 stdin과 같은 buffer, .py로 끝나는 python file이다. python interpreter는 string으로 읽어오고 string으로 저장한다. file이던 buffer던 python interpreter는 string을 읽고 string을 쓴다. 그런데 이 설명은 조금 공허해 보인다. 그리고 의문점도 든다. computer에서 file과 buffer는 모두 binary code로 되어 있는데, string을 처리한다는게 와닿지 않는다.
python grammar basic
from과 import
직관적 이해
어떤 code를 보더라도 from import, import와 같은 구문을 볼 수 있다. 이것을 이해할 수 있어야 한다. module과 package를 직관적으로 이해해보자.
import sys
import os
import만 사용될 때,
- 뒤의 인자는 module이거나 package다. 참고로 sys는 module이고 os는 package다. sys와 os를 path에서 찾는다. 그리고 eval()한다.
- import만 사용하면 name space를 갖는다. module.symbol형태로 사용한다.
import numpy as np
- import 뒤에는 module or package가 온다. numpy라는 module을 path에서 찾고 eval()한다.
- as를 사용해서 namespace를 np로 변경한다. np = numpy모듈객체 생성으로 봐도 된다.
from math import pi,square
from이 사용되는 경우,
- from 뒤에는 module이 온다. path에서 math module을 찾아서 eval한다.
- import뒤에는 name(symbol)이 온다.module이나 package가 올수 없다.
- name space를 사용하지 않는다. pi, square 직접 사용한다.
module, package 찾기
import sys
print(sys.path)
['', '/opt/homebrew/anaconda3/lib/python311.zip', '/opt/homebrew/anaconda3/lib/python3.11', '/opt/homebrew/anaconda3/lib/python3.11/lib-dynload', '/opt/homebrew/anaconda3/lib/python3.11/site-packages', '/opt/homebrew/anaconda3/lib/python3.11/site-packages/aeosa']
python interpreter가 초기화 될 때, sys의 path를 os의 environment variable PATH를 읽어서 세팅하다. 그래서 import문을 보면 load할 module이나 package의 위치를 찾을 수 있는 것이다. 만일 package나 module을 만들고 참조하려면, sys.path 경로에 module이나 package를 위치시키면 된다. 참고로 package는 init.py가 있는 폴더를 말한다. 이 package가 site_packages에 있어도 참조가 되는데 site_packages는 pip나 conda가 package를 설치하는 위치다.
assignment
개념
assignment는 code를 읽거나, code를 작성할때 반드시 보게되는 문장이다. assignment에 대해 한마디로 정의하자면, 객체를 생성시키는 operator다. data type에 따라서 객체는 다양한 구조를 갖고, 따라서 객체 생성 방식은 다양하다. int,float,string,tuple,list와 같은 python에서 기본적으로 주어지는 data type에 대해 살펴보자. 기본적인 data들이 assignment를 통해서 메모리에 구조화 되는지 내부동작을 직관적으로 이해할 필요가 있다.
int
-
assignment 예제1
a = -2이것을 보고 내가 직관적으로 느끼는 것은 -2라는 literal을 보고 integer객체를 만들고, 그 객체와 a라는 symbol을 묶어서 symbol table에 저장한다는 것이다. 그러나 이것은 정확한 설명은 아니다. 정확한 설명을 위해선, 어느 정도의 내부구조를 알아야 한다.
우선, python interpreter가 a=-2이라는 코드를 해석하기에 앞서서, python interpreter에게 인자가 주어진다. 인자로 주어지는것은 위의 예처럼, a = -2라는 code를 포함하는 stdin이라는 buffer이거나 .py라는 file이다. file이나 buffer나 내부적으로 진짜 구성되어 있는것은 모두 bit sequence다. 즉 0과 1의 비트로 이루어진 byte들로 구성되어 있다. 그런데, 그런 file을 editor로 열거나, stdin버퍼에서 input()나 read()같은 함수를 사용해서 읽은 결과를 보면 모두 string이다. 어떤 일이 벌어진 걸까? file이나 buffer는 자신의 민낯인 bytecode를 절대 보여주지 않는다. 자신이 어떤 문자열로 보여지고 기록될지를 encoding으로 나타내는데, 이 encoding을 사용해서 string으로 보여준다. 그래서 file이나 stdin과 같은 buffer에 있는건 그냥 string이라고 생각한다. 하지만 진짜 민낯은 모두 bit열로 되어 있다는 것이다. file이나 buffer에는 encoding rule이 적혀 있어서 사용할때는 encoding rule을 기술해야 한다.
여튼 stdin에 a = -2는 stdin버퍼에 있고, 이것이 python interpreter의 입력이 되어서 token으로 만들고 parsing tree를 만든다. sentence마다 parsing tree가 만들어지고 이를 eval하게 된다. 여기서는 a=3이라는 하나의 sentence에 대한 parsing tree밖에 없다. 여튼 이제부터 처리과정을 살펴보자.
보통은 오른쪽의 -2라는 값을 읽고 int객체를 생성한다. 그리고 객체의 생성자에게 -2값을 전달해서 -2라는 객체를 만들거라고 생각한다. 그런데 python에서 integer객체는 바로 객체를 생성하지 않는다. python은 속도를 위해서 cached라는 array linked list를 heap에 가지고 있다. cached array에는 -5 ~256까지의 값을 갖는 int object를 유지하고 있다. 그래서 cache에서 가져온다. 내가 여기서 cache array list라고 한 얘기는 cache에 있는 item들은 array처럼 32비트 거리만큼 연결되어 있기 때문이다. 그런데 struct를 보면, linked list처럼 pointer로 연결되어 있다.
a = 1 b = 2 print(id(1)) print(id(2))4345849048 4345849080따라서 heap에 integer객체를 새로 생성하지 않는다. 그림을 보자.
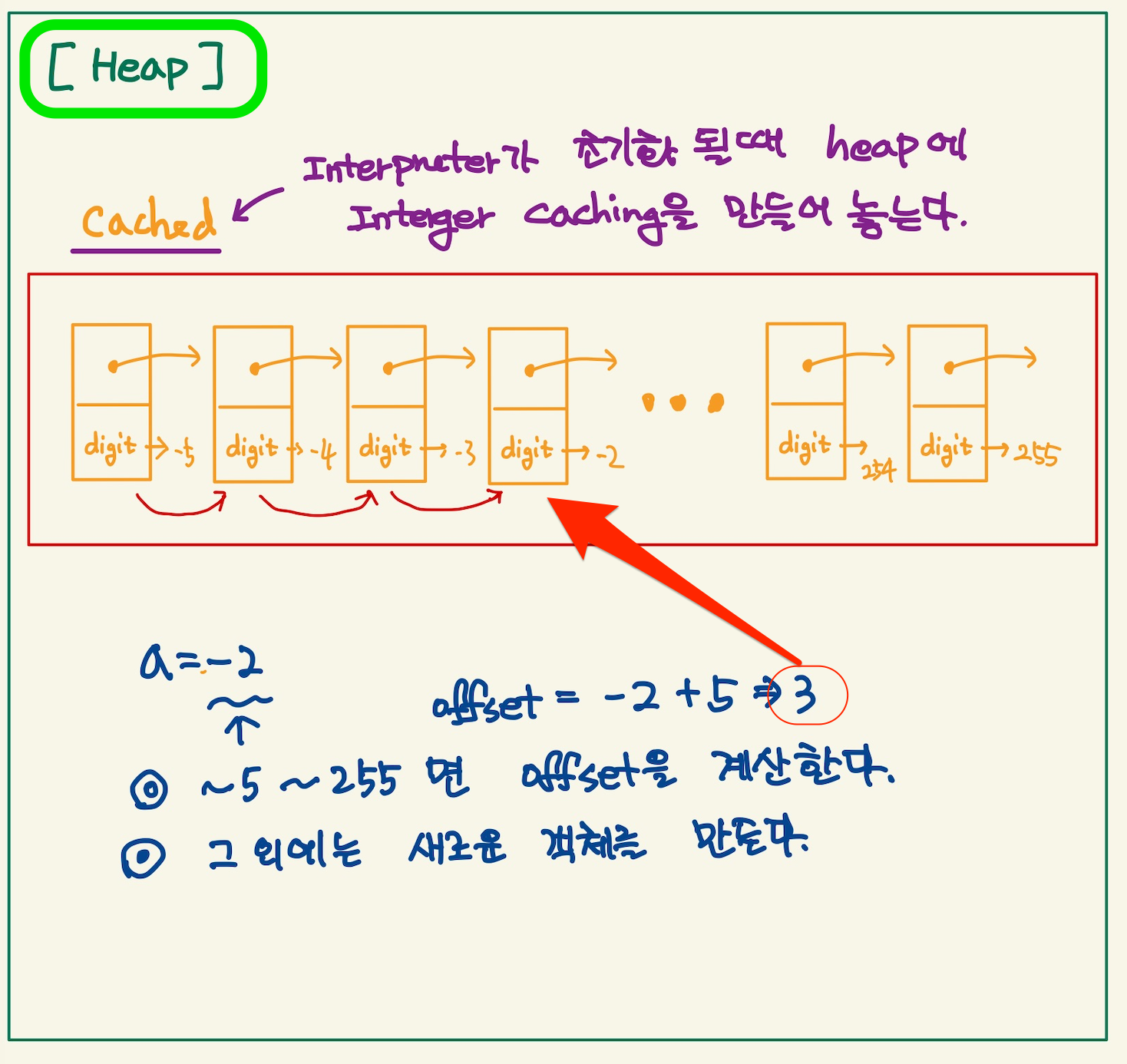
Figure 4: integer cached
-2라는 값과 offset을 더해서 이미 만들어진 int 객체를 a라는 symbol이 가리킬 뿐이다.
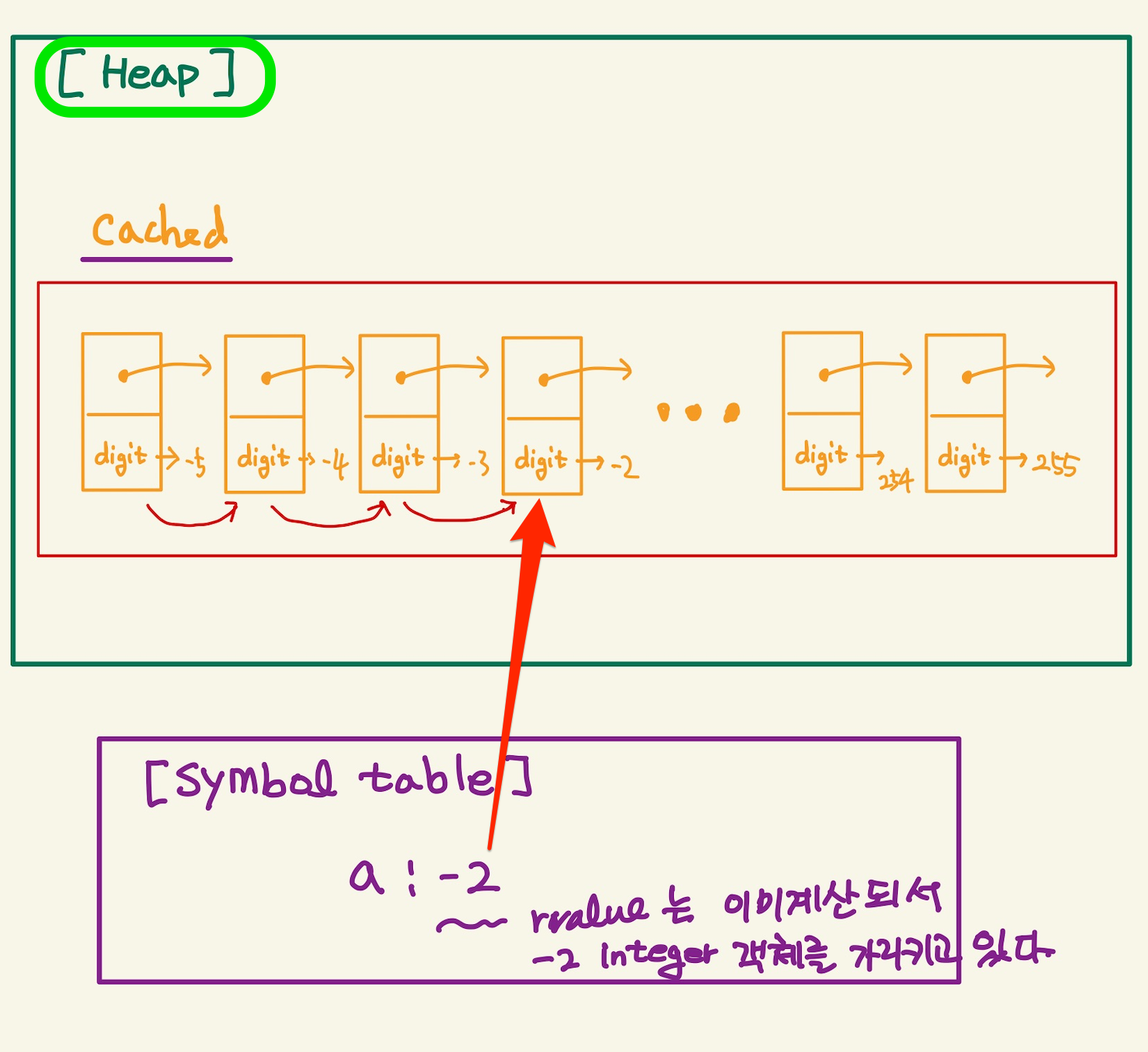
Figure 5: integer cached2
위 그림을 보면, rvalue인 -2는 이미 evaluate되어서 heap에 있는 integer객체에 대한 pointer를 return한다. 그리고 a와 2가 가리키는 heap있는 integer객체를 symbol table에 등록한다.
-
assignment 예제2
a = 500-5~255까지의 정수는 heap의 cache라는 영역에 이미 만들어진 integer객체를 재사용한다. 그렇다면 500처럼 범위에 포함되지 않는 int는 어떻게 할까? 새로운 객체를 만든다. int 객체는 어떤 형태인지 알아보자.
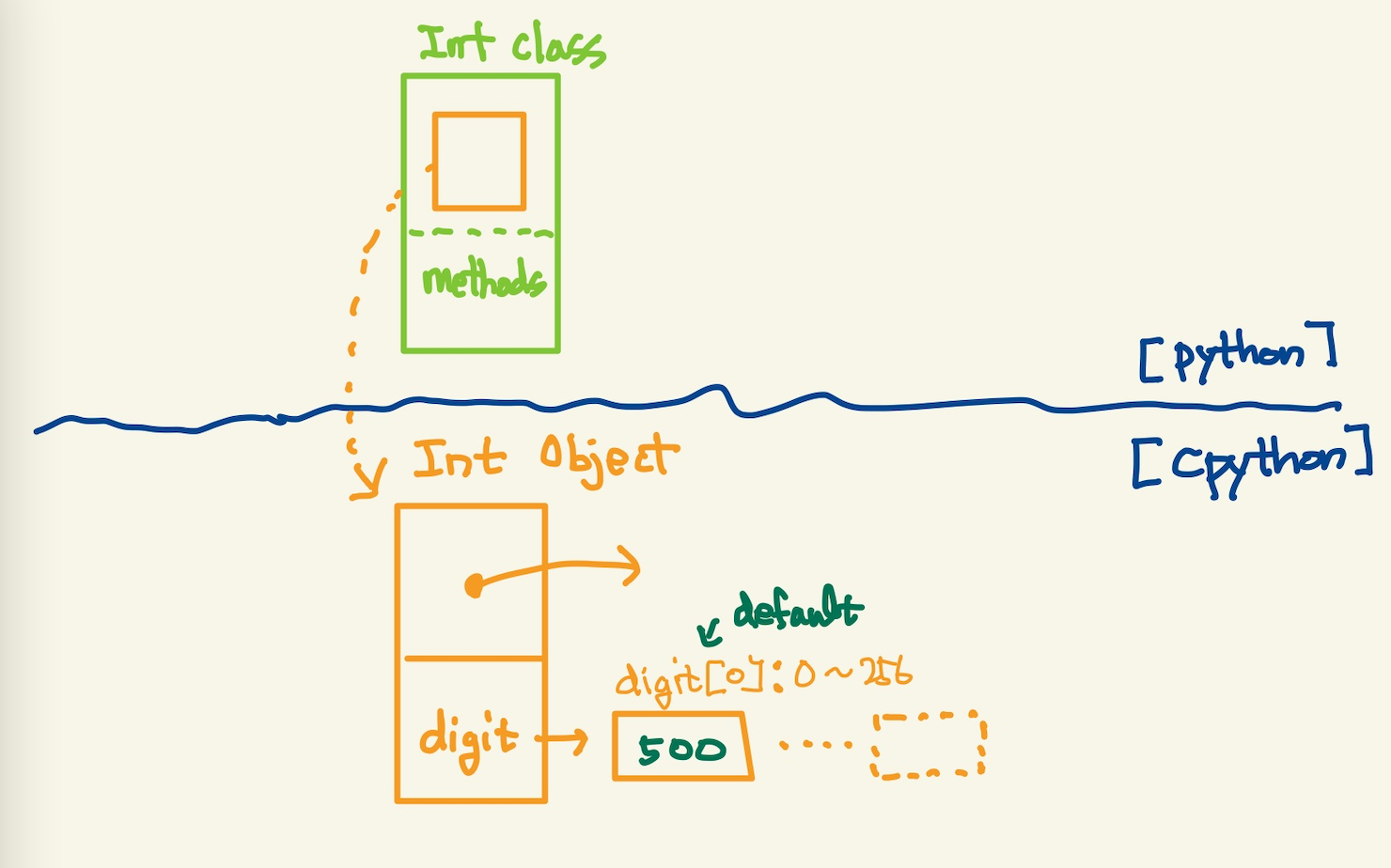
Figure 6: integer1
int객체는 단순하다.500이라는 값을 갖는 객체를 만든다. 객체를 만들면 heap에 위치한다. symbol table등록하는 과정은 아래와 같다.
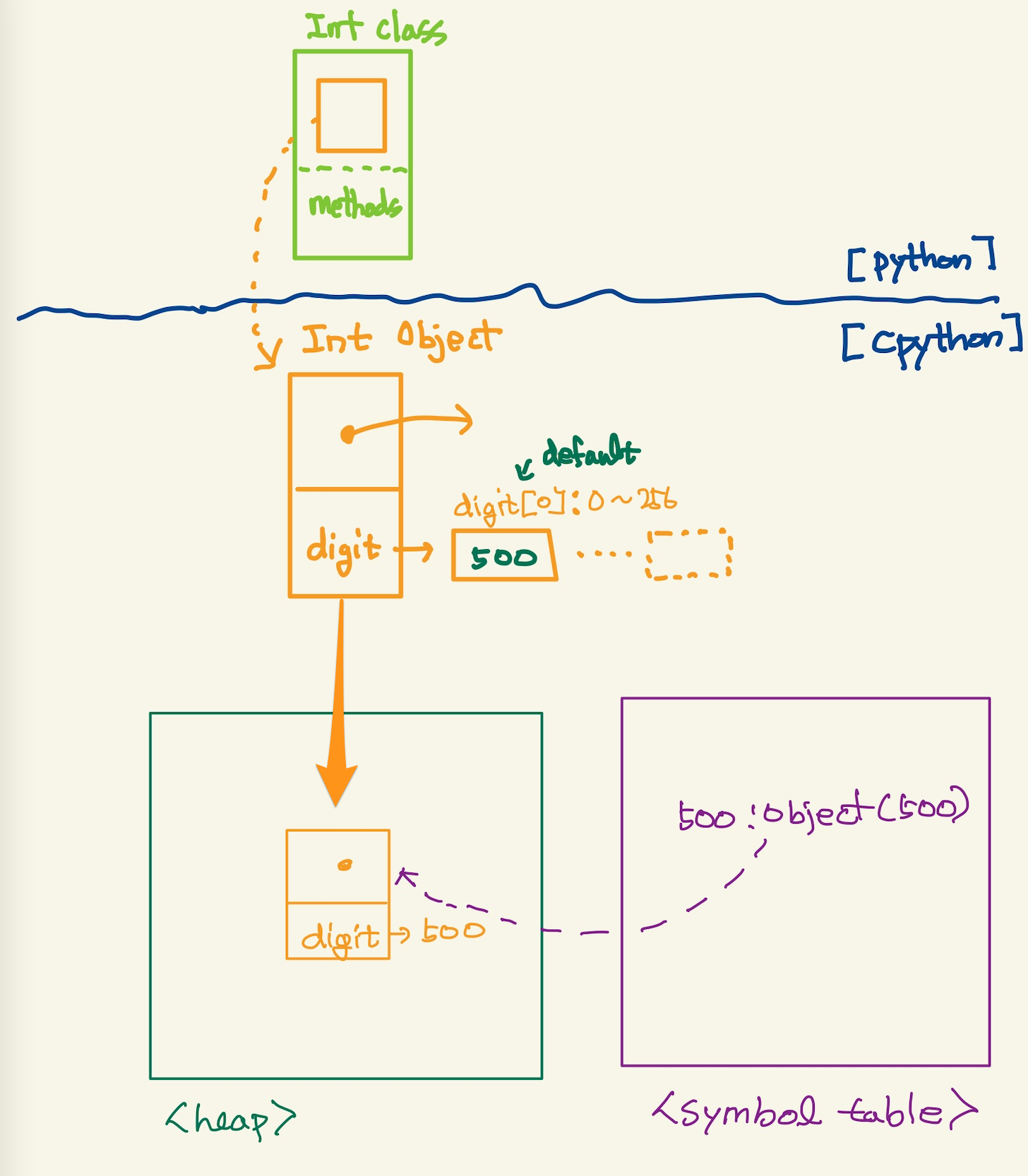
Figure 7: integer2
위에서 cpython에서 int struct의 경우 cpython에서 코드로 확인할 수 있다. cpython의 source code에서 int개체의 원형인 c의 struct는 다음과 같이 되어 있다. 예전에는 int struct였지만, 지금은 내부적으로 long을 사용한다.
;;python_source/Python-3.10.12/Include/longintrepr.h struct _longobject { PyObject_VAR_HEAD digit ob_digit[1]; }; ;; python_source/Python-3.10.12/Include/longobject.h typedef struct _longobject PyLongObject; /* Revealed in longintrepr.h */
-
assignment 예제3
import sys print(sys.version) a = 100 b = 100 print(a is b) c = -100 d = -100 print(c is d)3.11.5 (main, Sep 11 2023, 08:31:25) [Clang 14.0.6 ] True True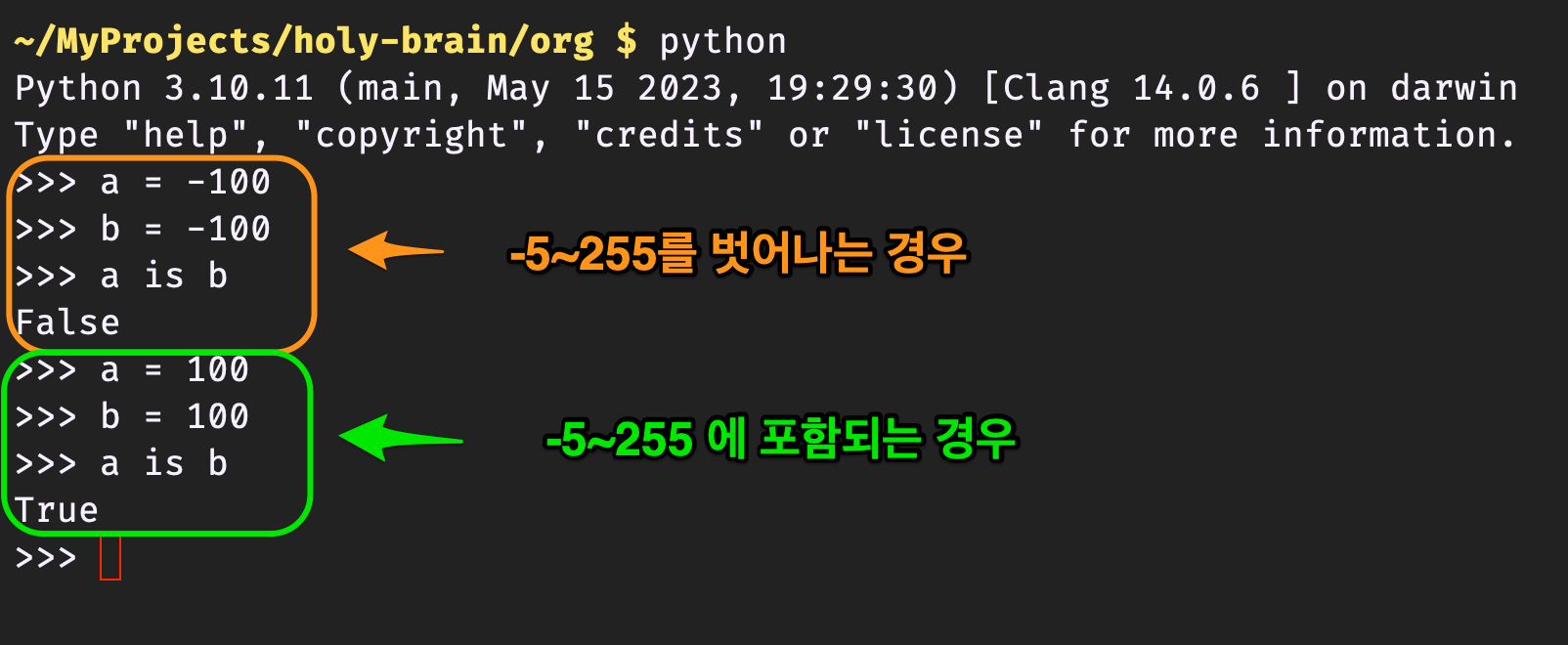
Figure 8: results
a = 100은 -5~255사이의 값이기 때문에 이미 heap에 있다. 따라서 객체를 새로 생성하지 않고, 바로 symbol table에 a:100을 저장한다.b = 100도 100이란 값이 이미 heap에 있기 때문에, 객체 생성을 하지 않고 symbol table에 b:100을 저장한다. a,b는 동일한 객체를 가리키기 때문에 a is b 는 True가 된다. 이것을 그림으로 표현하면 다음과 같다.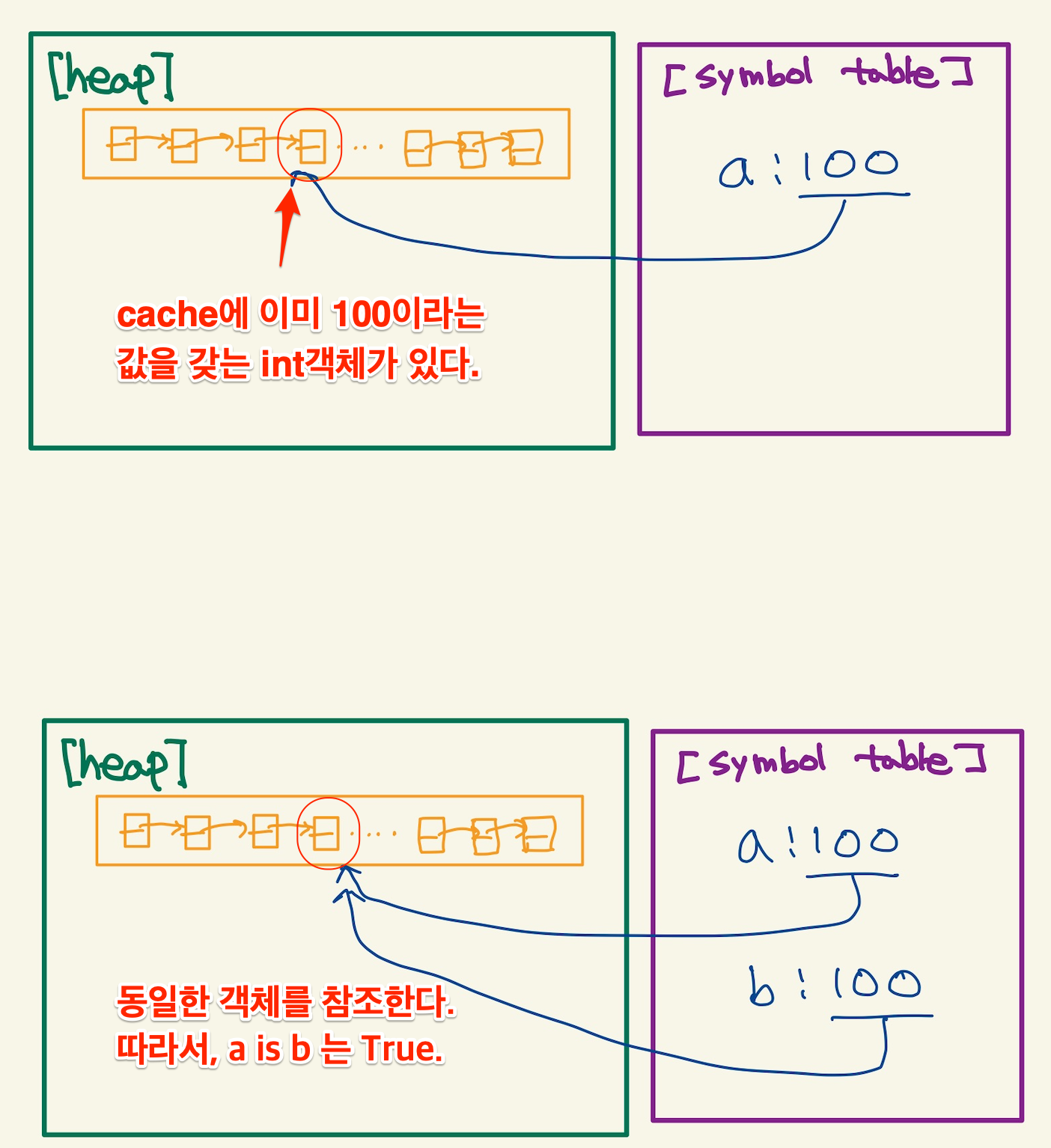
Figure 9: a is b
c = -100은 -5~255에 포함되지 않는다. 따라서 heap에 객체를 생성한다.d = -100도 새로운 객체를 heap에 생성한다. 따라서 객체의 주소를 비교하는 c is d는 False를 갖게 된다. 그림으로 보면 다음과 같다.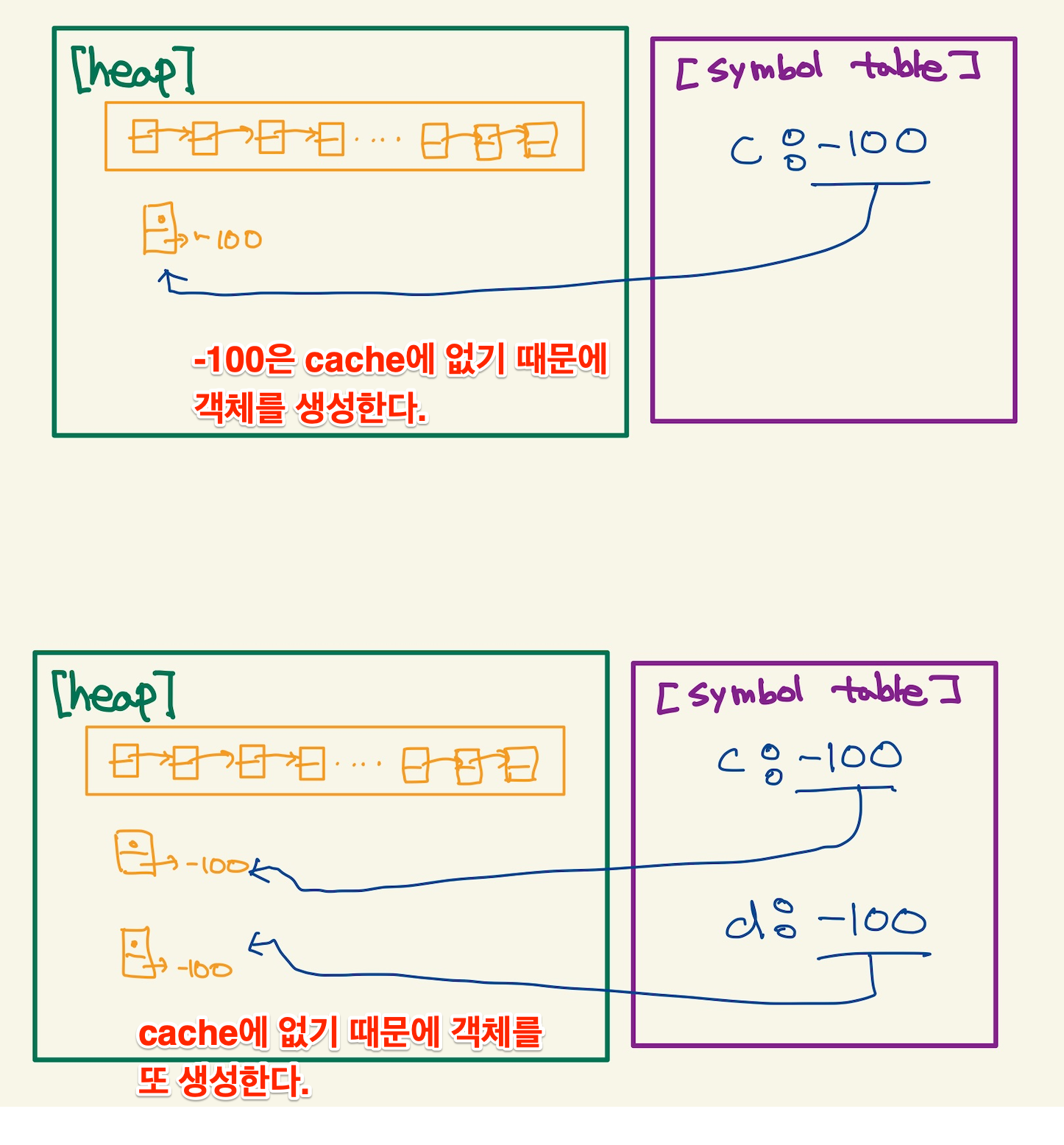
Figure 10: c is d
-
4칙 연산
python에서는 모든것이 객체다. 따라서 4칙연산이 값의 계산이라기 보단 객체간의 계산으로 볼 수 있다. 같은 int type의 계산이라는 전제하에 다음을 생각해보자.
a = 3 + 5위 코드를 보고 a = 8 이라는 것을 모르는 사람은 없다. 그리고 그렇게 해석하고 넘어가도 된다. 좀더 구체적으로 3과 5를 더해서 8이 나왔고, 8은 cache에 이미 만들어져 있기 때문에 가져온다고 말해도 된다.
그런데 python에선 3,5를 단순히 value의 계산으로 보지 않는다. 3,5는 객체다. 따라서 python interpreter가 객체에서 어떤 과정을 통해서 evaluate하는 것을 알아야 한다. 3이란 digit을 보고 interpreter는 cache에 3이란 값을 갖는 객체가 있기 때문에 offset을 계산할 것이다. 아마도 3+5를 통해 8번째에 위치한 객체를 가리키고, 5도 cache에 저장되어 있기때문에 offset을 계산하면 5+5=10, 10번째 위치한 객체를 나타낸다는 것을 알것이다. + 는 2개의 객체에 대한 offset계산을 한다고 보면 된다. 즉 rvalue 3+5의 계산은 offset끼리의 연산이다. 8 + 10 = 18로 offset은 계산되고 18번째 객체의 주소와 a는 symbol table에 mapping될 것이다. return되는 객체의 주소는 값과 같다.
a = 500 + 30그렇다면 -5~255범위에 포함되지 않는 경우는 어떻게 되는가? 이것도 마찬가지로 500에 30을 더해서 530이 나오고 530은 범위에 포함되지 않으니 int객체를 만든다고 이해하면 된다. 더 구체적으로는 위와 같이 offset계산도 생각해야 하지만, 이 정도로도 덧셈은 충분하다.
a = 500 -30그렇다면 뻴셈은 어떨까? 뻴셈도 덧셈으로 보면된다. -30이란것도 2의 보수를 사용하면 양수로 처리되기 때문이다. 여튼 500 -30은 470이다. 이것은 -5~255범위에 포함되지 않기 때문에 470을 갖는 새로운 int객체를 만든다.
곱하기도 마찬가지다. 곱하기도 덧셈의 일종이기 때문이다. 그러면 /은 어떻게 동작하는가?
a = 500 / 23 print(a)21.73913043478261500이라는 값은 binary로 나타낸다. 23도 binary로 나타내진다.
a = bin(500) b = bin(23) print(a) print(b) print(500 << 23)0b111110100 0b10111 4194304000
packing and unpacking
packing과 unpacking은 assignment와 연결되어 있다. assignment가 객체를 만들고 symbol table에 symbol을 등록만 하는게 아니라, 여기에는 packing unpacking개념이 녹아 있다. 즉 assignment는 packing, unpacking이 수행해서 객체를 만들고 symbol table에 저장한다. 예를 들어보자.
a,b,*cs = 1,2 #unpacking이 모자라는 경우
print(a)
print(b)
print(cs)
a1,b1,*cs1 = 1,2,3,4,5,6 #unpacking이 남는 경우
print(a1)
print(b1)
print(cs1)
1
2
[]
1
2
[3, 4, 5, 6]
rvalue는 1,2다. 이것은 (1,2)로도 표시될 수 있다. ()는 생략된 것이다. ()가 있다고 생각하면, 이것은 primitive data를 ()로 packing한 것이다. 여기서 tuple객체가 만들어진다. tuple객체가 처음 생성되면 데이터를 위한 4개의 slot이 만들어진다. 여기에 1,2가 저장되어 있다. 그 다음 lvalue를 보면 여러개의 변수가 보인다. assignment에서는 이런경우 unpacking이일어난다. unpacking이라는 것은 tuple 객체가 가지고 있는 값들, 여기서는 list형태로 저장된 4개의 slot에서 값을 꺼내서 a,b에 할당한다. *cs에서 *는 list packing operator다. 정규식의 *와 비슷하다. 만일 할당될 값이 많다면 그 값을 list형태로 packing한다. 만일 할당될 값이 적다면 []를 갖는다. *는 unpacking될 구조의 원소가 할당될 변수보다 많거나 적을때 탄력적으로 할당하게 해준다.
a = 1,2,3
print(a)
c,d,e = a
print(c)
(1, 2, 3)
1
s1 = "abcd" #packing
s2 = str("abcd") #s1과 같은 의미
d1 = { 'a': 3, 'b':4} #packing
d2 = dict(a = 3, b =4) # 객체
b = (1,2,3)
c = {1,2,3}
l = [1,2,3]
위의 literal들은 packing이라고 부른다. packing은 data item들을 value로 갖는 data structure 객체를 생성하는 것이다. 그래서 보면, literal로 객체를 생성할때는 item들이 primitive data value로 구성되어 있다. 반면에 객체를 직접사용하고 argument로 설정하는 경우, symbol을 사용할 수 있다.
a,b,c,d = "abcd"
print(a)
e,f,g,h = [1,2,3]
print(e)
a
float
print(5 == 5.0 == 5)
True
print(False == False) in [False]
True
print(False == (False in [False]))
False
print(False == False in [False])
True
print(5 == 5.0 > 4)
True
print(.1+.1+.1 == .3)
False
print(.1+.1 == .2)
True
print (5 == True)
False
print(True > 4)
False