
python_summary2-assignment and variables
variable & operator
변수 개념
python에서의 변수를 lisp에선 symbol이라고 부르고, 일상생활에서는 name이라고 말한다. 일상생활에서 name은 중요하지 않다. 본질이 중요하다. 어떻게 부르던 본질은 변하지 않기 때문이다. 그러나, logic과 computer science는 말장난이기 때문에 name은 그 무엇보다도 중요하다. 그래서 변수, symbol, reference 등등 다양하게 부른다. 다르게 부르는 이유는 다르기 때문이다. 언어가 다르고 쓰임새가 다르다. 하지만, 여기서 우리가 알아야 하는것은 name이 본질을 가리키는 것이 아니라, 가리키는것 자체가 본질이라는 것이다. logic과 cs에서는 그렇다. symbol이던 변수던 모든것을 가리킬수 있다. 그것이 class가 되었던, macro가 되었던, primitive datatype이 되었던, function이 되었던 method가 되었던 모든것을 가리킨다. 이것이 본질이다. first order logic의 Frege가 말한 concept라는것은 어떻게 보면 가리키는 것이 본질이라는 것을 말하는지도 모르겠다.
python의 변수를 다루기 전에 lisp에서 변수에 해당하는 symbol을 살펴보자. lisp에서 모든 symbol은 동일한 형태의 structure를 갖는다. 그림을 보자.
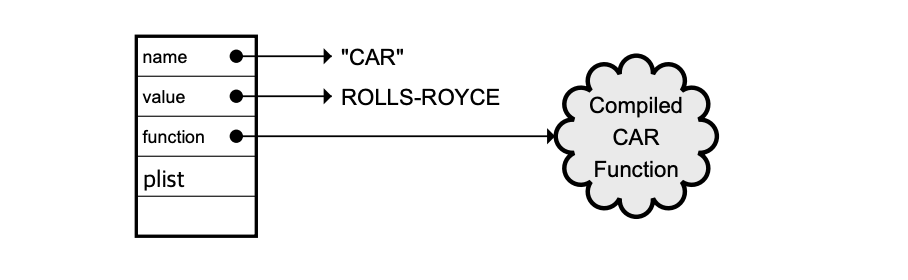
Figure 1: the structure of symbol
symbol의 이름은 unique하다. python에서 symbol은 변수라고 부르는데, 대부분의 사람들은 대략적으로 다음과 같은 구조를 가지고 있을거라고 생각한다. 예를 들어서
a = 3
위의 문장을 python interpreter가 해석하면 아래와 같은 모양일 것이라고 생각한다.
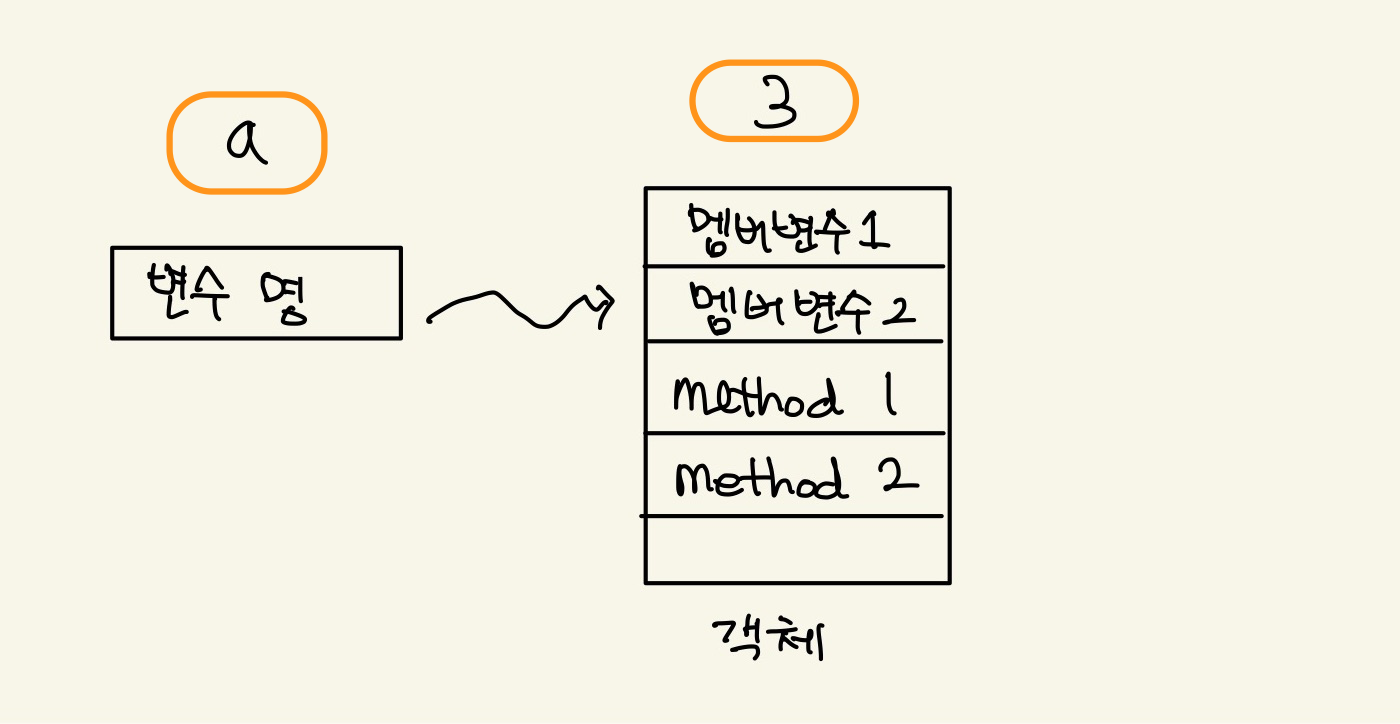
Figure 2: python symbol
그러나 위 모양은 assignment가 적용되기 전의 모습이고 적용된 이후의 모습은 아래와 같다고 생각한다.
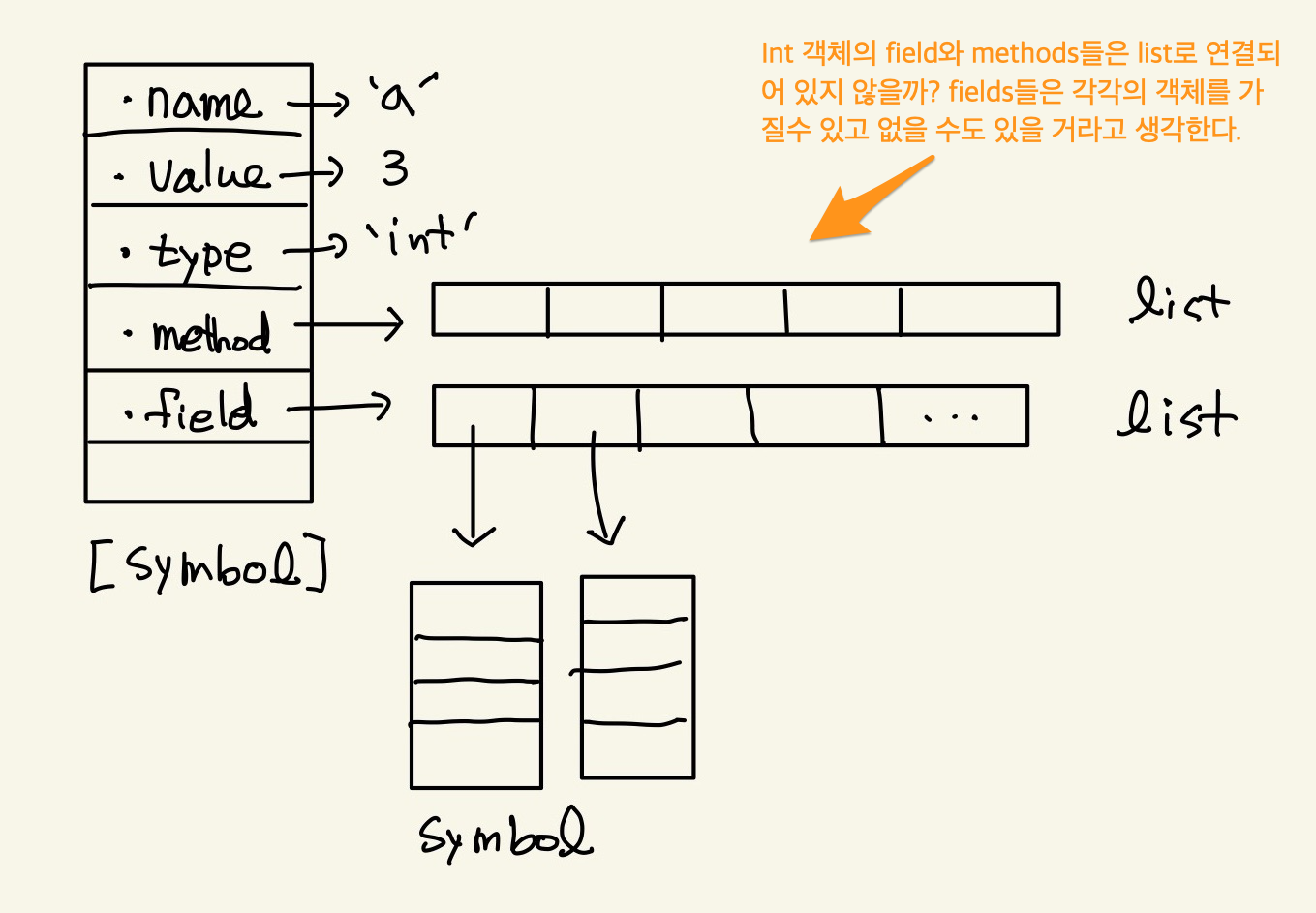
Figure 3: python symbol2
어떤 객체의 name에 변수명이 삽입된 형태가 아닐까 한다. 음…python에서는 모든게 객체다. 예외가 있다면, python interpreter를 위한 axiom같은 built-in functions과 operators들뿐이다. 따라서 a라는 변수는 class여야 한다. 그런데 a는 class가 아니다. 예전에는 Symbol이라는 class가 있었으나, 지금은 존재하지 않는다. 변수가 symbol이라는 class로 존재한다고 가정하자. 그러면 그 class의 instance를 만들거나 literal object가 있을것이다. 마치 Int라는 class가 있어서 3이란 literal object가 있듯이 말이다. 이것은 코드로도 보일 수 있다.
a
위 코드의 실행결과는 무엇일까? 실행되지 않는 에러가 난다.
Traceback (most recent call last):
File “<stdin>”, line 1, in <module>
NameError: name ‘a’ is not defined
a 라는 name, symbol은 정의되지 않았다고 한다. 위 그림처럼 name이 어떤 객체의 name속성으로 들어가서 객체의 일부분이 되어야 하는데 그렇지 않다는 얘기다. 그러면 assignment로 정의가 되어서 하나의 객체에 변수가 포함된것을 코드로 확인할 수 있는가? 확인할 수 있다.
a = 3
print(id(a))
print(id(3))
- #+RESULTS:
- 140712462129520
- 140712462129520
위와 같이 a의 address와 3의 address가 같다는것을 알수 있다. python에서 변수는 assignment를 통해서 객체에 이름을 붙인다고 생각하면 된다. 이름없는 객체에 이름을 붙이거나, 이름있는 객체에 이름을 바꾸는 것이다. 참고로 여기서 보여진 python의 변수와 object와의 관계는 내 뇌피셜이다. 반면 lisp은 gentle common lisp책을 참조했다.
옆길로 많이 샛지만, python의 변수나 lisp의 symbol이나, "이름으로 모든것을 가리킬수 있다는게 중요하다." 이름으로 객체도, class도
function도 method도 모든 것을 가리킬수 있다. 그게 본질이다. 여튼
그러면 이름과 구조를 연결해서 가리킬 수 있는 assignment에 대해서
알아보자. assignment는 python에서 객체가 아닌 변수, 객체가 아니라서
대접받지 못하는, 대접받는게 아니라 객체가 아니기 때문에 python에서
아예 사용할 수 없는 변수를 assignment를 해서 객체에 삽입한다.
변경 사항
위에서 python의 변수와 객체의 관계를 2개의 그림으로 표시했었다. before & after인데, assignment가 수행되었을 때 하나의 객체에 변수가 name으로 추가된다는 설명을 했었는데, 그건 아닌거 같다. 왜냐면 여러개의 변수가 하나의 객체를 가리키는 경우가 많은데 예를 들면 primitive data들은 거의 모두 동일한 객체에 대해서 여러 변수들이 가리킬 수 있다. 나는 객체가 name list가 있다고 했는데, symbol table이 있기때문에 객체가 name list를 가질 필요가 없다. 예를 들어서 symbol table에 a:3, b:3, c:3이 있으면 되는것이지, 3이라는 객체에 name list [a,b,c]를 유지할 필요가 없기 때문이다. 내가 lisp의 symbol 구조와 python은 비슷할 거라고 생각하고 추측했기 때문이다. 정정하면 python의 assignment는 before의 그림으로 설명이 된다.
python assignment operator
변수와 assignment의 개념
python에서 모든 것은 객체다. 그런데 예외가 있다. "operators와 built-in functions, 그리고 지금껏 말했던 변수는 객체가 아니다."
python interpreter(cpython)는 c로 작성되었고 그 중 일부는 class가
없다. c의 것을 그대로 wrapping해서 사용한다. 그래서 operator들은
중위연산 표기법을 쓴다. 아무래도 그 유산인듯하다. 여튼 "assignment는 위에서도 정의했듯이 객체를 생성하고 객체에 이름을 붙이는 operator다."
assignment문장을 python interpreter는 evaluate하는데, eval()를 봐도
알겠지만, 문자열을 입력으로 받는다. 입력으로 받은 문자열을 value로
return하는게 아니라 객체를 생성하거나 이미 있는 객체로 부터 value를
가져오는 것이다. 그리고 객체를 생성한다는 말은 객체의 생성자를
실행한다.
assignment는 lvalue와 rvalue를 =기호를 사용해서 다음과 같이 표현한다.
lvalue(symbol) = rvalue
python interpreter는 = 이라는 문자를 보고 assignment로 알고 여러가지 처리과정을 거친다. 객체에 이름을 붙인다는 것은 code의 어디서나 참조할 수 있게 한다는 말인데, 그렇게 하기 위해서 symbol table이라는 dictionary를 사용한다. 이름과 객체의 주소를 mapping해서 symbol table에 저장하면, code의 어느 위치에서도 해당 symbol을 access해서 사용하는 것이 가능하다.
a = 3
b = [1,2,3]
print(b)
python interpreter가 assignment operator를 보고 해석하는 과정은 복잡하다. symbol table과 cache, string interning같은 개념에 대한 이해가 필요하기 때문이다.
우선 interpreter는 rvalue를 처리한다. 3이 있는데, 이것은 Int
객체다. 언뜻 생각하기에 literal value라서 3으로 해석되고 객체 생성은 안할꺼 같지만, 객체 생성을 하는게 assignment operator의 동작방식이다.
function이 주어지면 function객체를 생성하고, class가 주어지면 객체를
생성하는게 assignment의 역할이다. 그래야만, 객체가 생성되면서 생성자
함수가 실행되면서 method나 field에 접근이 가능하기 때문이다. 그런데
literal value는 좀 특이하다. oop언어에서 literal value는 value인
동시에 객체다. functional language에서는 literal value는 value인
동시에 function이다. 이것은 church numeral을 참조하기로 한다. rvalue는
interpreter가 해석한 후 해당하는 객체를 생성한다. 그런데, primitive한
data type을 갖는 literal 객체를 매번 생성하는건 비효율적이다. 그래서
java에서는 primitive한 data type의 객체이거나 string의 경우 pool을
만든다. 속도 때문이다. python도 그럴까? python은 일부 primitve data
type객체의 경우 pool 대신에 cache에 이미 만들어진 객체를
저장한다. 예를 들면 -5~255사이의 정수 객체들은 cache에 이미 만들어져
있다. string의 경우 재사용을 위해서 string pool과 같은 string
interning을 사용한다. 다시 rvalue를 어떻게 처리하는지 보자. python은
3을 보고 3을 값으로 하는 Int객체를 만든다. 3은 Int객체를 만들필요 없이
cache에서 가져와서 사용한다. 만일 500이라면 int class 생성자를
호출해서 500을 value로 설정하는 객체가 만들어졌을 것이다. 작은
정수들은 이미 cache에 있다. 그래서 cache에 있는 객체 3을
가져온다. 그리고 evaluate해서 3이란 값을 얻는다. 그런 후에 a라는
symbol과 Int객체 3의 value인 3을 mapping해서 a:3을 symbol table에
등록한다. 참고로 symbol table은 locals()와 globals()로 확인이
가능하다. 반면에 cache에 저장된 값들은 확인할 수 없다. cpython의
소스코드를 확인해야 한다. 여튼 요약하면 rvalue를 보고 cache나 heap에서
객체를 꺼내거나 생성한 후, lvalue와 함께 symbol table에 등록하면
interpretion이 끝난것이다.
참고로 symbol table은 dictionary다. key와 value를 가지고 있다. dictionary의 key에는 심볼을 value에는 객체를 evaluate한 결과를 mapping해서 넣는다. primitive data type 객체와 string,list같은 것들은 evaluate하면 value가 나오지만, 그렇지 않은 객체들은 address가 evaluate의 결과값이 된다.
이전 그림에서 객체는 value라는 항목이 있다고 얘기했는데, 그래서 일반 객체는, value항목에 address가 있고, primitive data들은 value항목에 value가 있다고 설명하기도 했는데, 객체에 value항목이 있는지는 모른다. lisp에 기반한 내 뇌피셜이다.
assignment를 이해하기 위해선 cache, symbol table개념을 이해해야 하는데, 아래는 symbol table을 확인하는 예제다.
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return self.name
# Person 클래스의 객체를 생성하고 값을 설정합니다.
person = Person("John", 25)
person.name = "Jane"
person.age = 30
a = 3
# 객체의 속성 값을 출력합니다.
print(person)
print(locals())
- #+RESULTS:
- Jane
- {’name’: ‘main’, ‘doc’: None, ‘package’: None, ‘loader’: <class ‘frozen_importlib.BuiltinImporter’>, ‘spec’: None, ‘annotations’: {}, ‘builtins’: <module ‘builtins’ (built-in)>, ‘file’: ‘<stdin>’, ‘cached’: None, ‘Person’: <class ‘main.Person’>, ‘person’: <_main.Person object at 0x7fd4312f57f0>, ‘a’: 3}
locals()는 local symbol table을 보여주는 함수다. global symbol table은 globals()가 제공된다. 위에서 보듯이 primitive type인 a의 경우는 값 3이 mapping되고 person이라는 class는 객체를 evaluate한 address값이 symbol table에 기록된다.
변수와 function assignment 개념
변수는 function도 생성하고 name으로 가리킬수 있다.
def foo():
print("foo")
print(locals())
- #+RESULTS:
- {’name’: ‘main’, ‘doc’: None, ‘package’: None, ‘loader’: <class ‘_frozen_importlib.BuiltinImporter’>, ‘spec’: None, ‘annotations’: {}, ‘builtins’: <module ‘builtins’ (built-in)>, ‘file’: ‘<stdin>’, ‘cached’: None, ‘foo’: <function foo at 0x7f87b6dd50d0>}
interpreter가 assignment를 보고 symbol table에 기록하듯이 function definition을 보고 symbol table에 기록한다. foo: function의 address로 저장한다. 여기서 function은 lambda function이다. lambda function도 python에는 heap에 저장되는 객체다. python은 모든게 객체이기 때문이다. 객체의 type은 function이란 type을 갖는다. 객체에는 모든 method와 field를 dir()로 확인할 수 있다. 그리고 foo라는 이름으로 dir()에 있는 method와 field를 접근할 수 있다.
예를 들어서 lambda function을 보자.
add = lambda x, y: x + y
print(type(add)) # <class 'function'>
print(dir(add))
변수와 assignment의 예 1
(1) a = 15
(2) b = a
(3) b
print(b)
(1)의 경우, 간단히 말하면, interpreter는 15를 evaluate해서 cache에서 15라는 값을 가져온다. 15라는 값이 -5~255사이이기 때문에 int객체를 cache에서 가져온다. 그리고 symbol table에 a:15를 기록한다.(2)의 경우 a라는 symbol에 해당하는 값을 symbol table에서 가져온다. 가져온 15는 그 자체가 value이면서 객체다. 15라는 value가 객체인것은 method를 실행할 수도 있고, memory에 위치한 주소도 갖고 있기 때문이다.
print(dir(15))
print((15).to_bytes(2,byteorder="big"))
print(id(15))
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__getstate__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'as_integer_ratio', 'bit_count', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
b'\x00\x0f'
4378338968
따라서 b와 15를 mapping해서 b:15를 symbol table에 기록한다. (3)의 경우는 evaluate하면 symbol table에서 b를 찾아서 가져온다. 15를 가져오지만, 그 값은 쓰여지지 않는다. 이후 print를 해서 그 값을 출력하면 15가 나온다. 좀더 확실한 확인은 locals(),dirs() 혹은 globals() 그리고 id()를 사용해서 확인할 수 있다.
변수와 assignment의 예 2 (mutable vs immutable)
(1) a = 1
(2) b = 1
(3) c = 1
(1)은 1을 evaluate하면 객체 1을 cache에서 가져온다. 그리고 a:1을 symbol table에 기록한다. (2)는 동일한과정으로 b:1을 기록한다. (3)은 c:1을 기록한다.
assignment는 객체를 만든다. (1),(2),(3)의 1이라는 객체는 매번 생성되는 것인가? 아니다. cache에서 만든 객체를 가져온다. (1)에서도 가져온 객체를 사용하고 (2)번도 가져온 객체를 사용한다. (3)번도… 그래서 3개의 1은 모두 동일한 객체다.
a = 1
b = 1
c = 1
print(id(a))
print(id(b))
print(id(c))
4312425688
4312425688
4312425688
반면에 아래의 예를 보자.
(1) a = [1,2,3]
(2) b = [1,2,3]
(3) c = [1,2,3]
(1)의 경우 list 객체를 생성해서 symbol table에 등록한다. (2)의 경우 동일한 값이다. 그러면 이전에 만들어진 객체를 재사용할 수 있을까? 안된다. 객체가 symbol table에 있는데도 불구하고 객체를 새로 만든다. (3)도 새로 만든다. id()로 주소를 찍으면 모두 다르다.
a = [1,2,3]
b = [1,2,3]
c = [1,2,3]
print(id(a))
print(id(b))
print(id(c))
4382545152
4382645760
4383305600
매번 새로운 객체를 만든다.
변수와 assignment의 예 3
a = b = 2
뒤에서부터 처리한다. 2라는 객체는 -5~255사이이기 때문에 cache에서 Int객체를 가져온다. b:2를 symbol table에 기록한다. 그 다음 a = b assignment를 수행한다. symbol table에 기록된 b를 가져온다. b의 값은 2라는 객체다. 따라서 a:2를 symbol table에 기록한다.
literal object에 대해서
python에서 literal value는 값이면서 객체다. 즉 3이나 5도 값이면서
객체다. literal value면서 literal object이다. 그렇기 때문에 아래와
같이 method호출이 가능하다. oop언어는 value가 객체고 functional language는 value가 function이다. lambda…
4.0.real or (4).real
위에서 보듯이 literal value는 객체이기 때문에 method호출이 가능하다. 4.0은 float객체고 real이란 float의 method다. ruby에서도 이렇게 하지만, 기존언어에서는 보기 힘들다. primitive data type의 객체들은 모두 literal object라고 할 수 있다. interpreter가 literal object를 evaluate하면 value가 나오는데 그 value는 객체다. 그러면 일반 object를 evaluate하면 무엇이 나오는가? 객체의 address가 나온다. 아래는 그 예다.
a = 3
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
p = Person("holy",20)
print(a)
print(p)
print(eval('a'))
print(eval('p'))
3
<__main__.Person object at 0x100d67650>
3
<__main__.Person object at 0x100d67650>
객체를 evaluate했을때, literal object와 일반 object의 차이를 설명하는 예제다. 원래 의도는 evaluate의 결과를 비교하는 것이다. 그런데 print()로 출력하는것과 evaluate의 결과는 다른거 아니냐고 말할 수 있다. print()는 인자로 주어지는 객체의 ‘str’ method를 호출하는것이지 evaluate한 결과를 보여주는게 아니지 않은가? 그래서 eval()도 사용해서 결과를 출력했다. 동일한 결과를 보여준다. ‘str‘을 재정의 하지 않는 이상 eval의 결과와 같다.
return하는 assignment
:=
(1) print((a = 2) == 2)
(2) print((a := 2) == 2)
(1)의 경우 python interpreter는 a=2를 수행한다. 2라는 int객체를
cache에서 가져와서 a:2를 symbol table에 저장한다. 그 다음 “\=== 2” 를
수행해야 하는데, 비교할 대상이 없다. 에러가 난다. 왜냐면 interpreter는
symbol table에 저장만 하고 다음 instruction으로 넘어가기
때문이다. (2)를 보자. interpreter는 “(a := 2)“를 수행한다. 2라는
Int객체를 가져오고 a:2를 symbol table에 저장한다. 그런 다음 a가
남는다. 그 다음 instruction은 (a)==2가 된다. “(a) = 2"를 수행하게 된다. interpeter는 a를 evaluate한다. 즉 value를 꺼낸다. 2 = 2가 되어
True를 갖는다.
여기까지 정리
아래는 예전에 쓴거라서 다시 review를 해야 한다.
primitive data types
python에서 primitive datatype의 객체는 속도를 위해서 미리 cache에 객체를 만들어 놓았다. 그리고 oop언어에서 primitive data 객체는 값이다. 이런 primitive data type은 다음과 같은 것이 있다.
python numerals type
- int,float,complex
- double은 없다. float가 double과 같다고 보면 된다.
다음은 numeral type의 예다.
int: 1,2,3
float: 1.7, -5.7, 4.67e-3, 3e5
complex: 1+8j, 1.6+8j
literal object는 바로 만들수 있다. 하지만 symbol이 없기때문에 참조할 수는 없다.
string
python에는 char type이 없다. 문자들은 string type의 객체일 뿐이다.
boolean
boolean literal object는 True,False인데 대문자를 사용한다는것에 유의하자.
True, False
None
다른 언어에는 없는 None이라는 객체가 있다.
None
연산자 (operator)
python의 모든 것은 객체라고 했다. operator도 객체일까? +,-,/ 같은 것을
보면 함수같다. 그런데 oop언어에 함수는 없다. method만 있을뿐이다. 그럼
method일까? 사용법을 보면 method형태가 아니다. method라면
객체.method형태로 사용할 것이다. 그럼 객체일까? 객체라면 +.abs()같은
method를 호출할수 있어야 하는데, 그런 것을 본적이 없다. operator는
과연 무엇일까? 내가 알고 있는 python의 모든 것은 객체란 말은
틀린것일까? 한가지 추론을 해본다. 연산자는 최상위 class인 Object의 method가 아닐까?
이것에 대한 얘기를 위해서 한적이 있다. python은 built-in functions과 operator, 그리고 symbol은 객체가 아니다. 이것들은 python interpreter에 제공되는 구조와 기능이고, c++에서 사용되는것을 wrapping한 것이다. 아래에서는 operator 얘기도 하지만, python의 구조에 대한 고민을 담고 있기때문에 수정하거나 갱신하지 않았다. 왜?라는 질문을 하고 고민을 하고 나중에는 답을 구하고 이런 과정이 계속되는데, 나중에 구한 답만을 기록한다면 고민을 하게된 과정이나, 고민을 해결하려 추론했던 과정들이 묻히는거 같아서 지우고 다시 쓰지 않았다.
python에서는 class선언 없이 코딩을 하곤한다. 예를 들어서, 아래 코드만 봐도, print()를 바로 호출한다. shell에서 interactive한 python을 실행할때 class를 정의할 수도 있지만, 그렇게 하지 않는다. file로 작성해서 python으로 실행할때도 class선언 없이 할수 있다. 그러면 의문이 들 수 있다. entry point가 없는 것인가? oop의 경우, 대표격 언어인 java를 보자. java에서는 class를 만들고 class에 public static void main()를 entry point로 해서 코드를 작성한다. c언어도 void main()로 entry point를 만들고 그 안에서 코딩을 한다. 그런데 entry point가 없다는게 신기하다. python이 oop언어라면, 아마도 print(3+4)를 둘러싸는 class가 있고, 그 class내의 entry point()가 있지 않을까 하고 생각한다. 다만 생략된 거 아닐까? 좀 찾아봤더니, 그렇다. 생략되었다. 아래의 print함수를 실행 시킬때는 python temp.py처럼 파일명으로 실행되고, python은 main라는 이름을 python에게 전달한다. 전달된 이름은 ‘name‘이라는 private member변수를 세팅한다. 그리고 temp.py내에서는 if name == main 아래에 print(3+4)가 있는 것이다.
print(3+4);
위의 코드는 아래 코드처럼 되어 있는 것이다.
class temp{
if __name__ == "main":
print(3+4);
}
그런데 이것과 연산자와 무슨 상관이 있는가?라고 말할 수 있다. print()에
보면 3+4에 + operator가 쓰였다. 이것이 어떤 syntax에러도 없이 수행되는
이유는, 숨겨져 있는 temp라는 class가 있고, 이 class는 Object라는
최상위 class를 상속받는다. 즉 +라는 operator는 Object class에서 정의된
method이기 때문에, 사용할 수 있는 것이다. 그래서 "내 생각은 + operator는 최상위 class Object의 method다."
그런데 위의 추론도 문제가 있다. + operator가 Object의 method이고
숨겨져 있는 temp라는 class가 Object를 상속하기 때문에 + method를
사용할 수 있다. 그런데 method의 인자가 3,4이다. 어떤 method가 이렇게
중위표기법으로 구현되는가? method의 중위 표기법 이상하지 않은가?
temp가 Object를 상속받기 때문에 + method를 사용한다기 보다, 3이라는
literal 객체가 Object를 상속받기때문에 + method를 사용할 수 있었고,
원래 표기법은 3.+(4)인데 저렇게 쓴게 아닐까? 지금까지는 100% 정확하게
operator가 무엇인지는 모르겠다. python에서는 모든게 객체라고 했는데,
operator처럼 그 존재가 정확히 모르는것 중에 built-in function이란게
있다. built-in function도 Object의 method인가?
gpt chat에 물어보면 operator와 built-in function은 python interpreter에 의해 제공되는 pre-builtin된 함수라고 한다. python interpreter는 python언어로만 작성되지 않았다. cpython이라고 해서 내부는 c,c++로 된 함수와 변수를 사용해서 만들어진다. python의 operator와 built-in function들(id,hash같은 함수), primitive data type은 c,c++에서 정의된것을 wrapping해서 사용된다. python의 모든것은 객체라고 말할때, 이말은 python으로 만들어지는 모든게 객체일뿐 interpreter에 미리 정의된것은 객체가 아닐 수 있는 것이다.
참고로 위에서 __name__은 object의 private field고, underbar가 한개인 것은 protected field이다. 그리고 python의 모든것이 객체라고 했는데, 참고자료가 있어서 attach했다. (참조:https://www.pythonmorsels.com/everything-is-an-object/#manually-calling-dunder-methods ),
연산자의 종류
-
arithematic operator
- +(덧셈)
- -(뻴셈)
- *(곱셈)
- **(거듭제곱)
- /(몫)
- //(몫,정수),
- %(나머지)
-
bit operator
- & (AND)
- | (OR)
- ~(NOT)
- ^ (XOR)
- <<, >>(SHIFT)
있다, 없다, 맞다, 틀리다의 정보는 bit로 나타낼 수 있다. 이런 정보는 bit 1개로 되어 있지 않다. byte,kbyte,극단적으로 GByte까지 엄청난 정보를 표현할 수 있다. 예를 들어서, 만명의 사람들을 일렬로 나열해서 코에 점이 있다 없다를 bit로 나타냈다고 하자.그리고 A라고 하자. 여기에는 사람을 나타내는 index정보와 점이 있다, 없다를 나타내는 정보를 표현한다. 동일한 만명인 사람들에게서 한국사람이냐 아니냐로 정보를 bit로 나타내고 B라고 하자. 한국사람이며 코에 점이 있는 사람을 알려면 and연산을 하면된다. 간단히 계산할 수 있다. 이것이 연산자의 힘이다. 한국사람이거나 코에 점이 있는 사람을 알고 싶다. 이것을 일일이 사람들을 확인할 필요가 없다. or연산을 하면 된다. 코에 점이 있는 사람들을 A라고 표시했는데, ~A라고 하면, 콤에 점이 없는 사람들을 표현할 수 있다. 몇명 인지는 1의 수를 세면 된다. XOR은 한국사람이면서 코에 점이 없거나, 코에 점이 있으면서 한국사람이 아닌 사람을 1로 표시한다. Nand, Nor도 상황에 맞게 사용할 수 있다. and or not xor은 있다,없다, 맞다,틀리다로 나타내는 명제를 수천개 수만개가 있어도 나열한 후 계산하면 된다. 근데, 실수로 수만개의 data의 이런 정보를 mega byte로 나타냈다고 하자. 그런데, 갑자기 한개의 bit를 추가해야 한다면? A에서 한칸 shift하면 된다. shift라는 것은 데이터의 삽입을 하기 위해서 사용된 연산인데, 10진수의 계산을 2진수로 변환후 shift연산을 하면 곱셈과 나눗셈을 기계적으로 더빠르게 할 수 있다. 그래서 shift는 원래의 의도인 data로서의 비트가 아니라 기계적 계산을 위한 연산자로 볼 수 있다. and or not같은 logical operator를 predicate logic에 한정지어서 말했는데, 실은 first order logic 참,거짓,있냐? 없냐의 명제가 아닌 first order statement를 계산할 수 있긴 하다. 물론, programmming language자체가 first order logic이고, 세상의 모든 knowledge는 first order logic으로 처리할 수 있기 때문에, logical operator는 중요하긴 하다. 얘기가 옆길로 빠져서…쓸데 없는 소리를 많이 했다.
-
연산자 축약
아래는 연산자 축약이라고 부르는데, 연산자 축약이란 말도 첨들어보지만, 코드는 익숙하기 때문에 용어는 그냥 넘어가자. 여튼 (1)하고 (2)가 같다는 것은 누구나 알 수 있다. (1)을 (2)로도 변환할 수 있고 (2)를 (1)로도 변환할수 있다고 알고 있다. 그런데 두 개의 연산은 python에서는 다르다고 한다.
(1) a += 1 , (2) a = a + 1기본적으로 (1)은
a가 가르키는 symbol table의 객체를 update하는 명령어? or 문장이라면, (2)는a가 가르키는 객체를 새로운 객체로 replace 문장이다.+=이란 기호는 assignment와는 다른 동작을 취한다는 것이다. (1)이 a가 참조하는 객체의 값을 update한다고 했는데, 만일 update할 객체가 immutable이라면 update가 되지 않고 생성이 된다. 즉 primitive data type의 객체를 참조하는 변수라면(1)과 (2)는 같은 것이다."(1)은 (2)와 같이 동작한다. primitive data type의 객체들은 immutable하기 때문에 (1)과 (2)를 구별할 필요가 없다.다음 예제를 보자.
a = 3 b = a a +=1 print(locals()){'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '<stdin>', '__cached__': None, 'a': 4, 'b': 3}a = 3은 assignment이기 때문에 새로운 객체를 생성하거나 update한다. 그리고 symbol table에 등록한다. 따라서 Int 객체 3을 생성하고 symbol table에 a:3을 등록한다. 그 다음, b = a를 수행 한다. a를 symbol table에서 가져오고 그 값을 b와 mapping해서 symbol table에 저장한다. b: 3이 등록된다. b= a에서 a를 interpreter가 evaluate하는데, symbol table에 a와 mapping된 객체에서 value를 가져온다. 근데 그 value라는게 일반적인 객체에서는 address다. 그런데 primitive data type의 객체들은 address가 아니 value를 따로 가져온다. primitive data type에서는 value의 값은 곧 address다.
value와 address는 같다.따라서, 역으로 symbol table에 저장할때 변수와 값을 저장하는데, primitive data type이 객체는 변수와 객체 주소를 저장하는데, 변수와 값을 저장한다. 이것은 변수와 객체 주소를 저장하는 것과 같은 의미다. 그 다음을 보자. a +=1을 하면 a가 가르키는(참조하는) 객체를 update한다.그런데 primitive data type이다. 이것은 a = a+1과 같다. interpreter는 rvalue의 a를 symbol table에서 가져온다. 가져온 객체는 3이란 값을 갖는 객체다. 그 객체에 1이란 값을 갖는 객체를 더한다. 객체와 객체를 더하면 append되거나 합쳐지는게 아니라, 새로운 객체를 만든다. primitive data type의 객체의 특징이다. immutable객체라 그렇다. 새로운 객체를 만들고 이전의 객체들로 부터 value를 더해서 4라는 value를 새로운 객체에 설정한다. 그런 다음 a:4를 symbol table에 등록한다. symbol table에는 이미 a:3이 있지만, 덮어써진다. key가 같기 때문이다. 따라서 symbol table에는 a:4만 있다. a:3을 a:4로 replace했다. 이것이 out-place다. 새롭게 만든다. 즉, 3이란 객체와 1이란 객체를 더할때, 3이란 객체에 값이 4로 update되는게 아니다.여기서 왜 b=a라는 문장은 왜 있는가? 위에서 test하는 것은 객체를 udpate하는 명령어 +=을 실행했을 때, a가 참조하는 객체가 변경되고, 그 객체를 참조하는 다른 변수(b)에도 영향을 미친다는 것을 보여주기 위해서다.
위에서 update 명령어를 수행했지만, 결과는 update되지 않았다. primitive data type 객체라서 그렇다. 다른 예를 보자.
a = 3 b = a a = a + 1 print(locals()){'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '<stdin>', '__cached__': None, 'a': 4, 'b': 3}이것은 일반적인 assignment를 수행한다. a = a + 1에서 rvalue를 계산해보자. a가 참조하는 객체 3을 가지고 와서 객체 1과 더한다. primitive 객체의 연산은 새로운 객체를 만들어낸다. 객체1에 있는 value를 객체 3의 value에 더하지 않는다. 객체 3을 update하지 않는다. 순차적으로 따라가면 다음과 같다.
a=3을 interpreter가 보고 a:3을 symbol table에 등록한다. 그 다음 b = a 에서 symbol table에서 a에 mapping된 객체 3을 가져온다. 그리고 b:3을 symbol table에 저장한다. a = a +1을 interpreter는 symbol table에서 a에 mapping된 3이란 객체를 가져온다. a = 3 + 1이 된다. 3과 1은 Int객체다. 객체를 더하는건데, 3이란 객체에 있는 3이란 value에 1이란 value를 더해서 4라는 값을 3이란 객체에 update하지 않는다. primitive data type이고 immutable하기 때문에 객체와 객체의 덧셈은 새로운 객체를 만든다. 따라서 4라는 값을 갖는 객체가 만들어지고, a:4를 symbol table에 등록한다. symbol table에 있는 a:3은 a:4로 덮어 써진다. 그리고 b가 가리키는 객체3은 변하지 않는다.
또 다른 예를 보자. 아래는 list 객체다. mutable한 객체다. mutable한 객체는 update문장에서는 객체를 update를 한다.
a = [1,2,3] b = a a += [4] print(id(b)) print(id(a)) print(locals())4310488320 4310488320 {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '<stdin>', '__cached__': None, 'a': [1, 2, 3, 4], 'b': [1, 2, 3, 4]}여기서 interpreter는 a = [1,2,3]에서 [1,2,3]이라는 객체를 생성하고 a:[1,2,3]을 symbol table에 등록한다. 그 다음, b = a를 보고, a를 symbol테이블에서 꺼낸 객체 [1,2,3]을 b와 함께 symbol table에 등록시킨다. 그 다음 a += [4]를 수행한다. update 문장이다. a가 참조하는 [1,2,3]이라는 객체를 꺼내와서 update를 한다. 즉 + [4]를 하면 [1,2,3]에 append되어서 [1,2,3,4]라는 객체로 수정된다.
다른 예를 보자. 이 경우는 assignment 문장이다. assignment는 update를 하지 않고 새로 생성한다.
a = [1,2,3] b = a a = a + [4] print(id(b)) print(id(a)) print(locals())4315108608 4315869056 {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '<stdin>', '__cached__': None, 'a': [1, 2, 3, 4], 'b': [1, 2, 3]}a = a + [4]에서 interpreter는 rvalue의 type에 해당하는 list 객체를 새로 생성한다. 그리고 a +[4]를 계산하여 새로운 객체에 [1,2,3,4]를 넣는다.
정리하면, +=, -=과 같은 update operator는 assignment operator와 arithmetic operator가 합친 형태다. assignment operator와 동일한 동작이라고 생각하기 쉬우나,다른 연산이라는 것을 기억해 두자. 연산자 축약이 축약하지 않은것과의 차이는 immutable 객체가 아닌 mutable객체에서 차이를확실하게 알수있다.
-
in-place:
-
out-place:
(1)의 경우는 out-place로 a라는 새로운 symbol과 무조건 새로운 객체를 만든다. 반면에 (2)는 in-place라고 해서 새로운 객체를 무조건 만들지는 않고 update할수 있는 객체라면 update를 하고 아니면 안한다고 한다. 이것은 mutable과 immutable하고도 연관이 있는듯 하다. python은 oop언어라서 모든게 객체다. 그중 primitive data type이라는게 있는데, primitive data type으로 만든 객체는 immutable하다. 즉 수정이 안된다. update가 안된다는 말이다. (1)번이야 무조건 객체를 만드니 객체를 새로 생성할지 안할지 고민할 필요가 없지만, (2)의 경우는 mutable과 immutable을 따지기 때문에 알 필요가 있다. a += 1에서 +=을 하나의 operator로 보자. lvalue에 해당하는 a를 symbol table에서 찾는다. 만일 a=3이라는 식이 위에 있어서 a가 3이라는 int 객체를 가리키고 있는 상황이라고 하자. 여기서 symbol table에서 찾은 lvalue a는 int type의 객체(value 3을 가진)를 가리킨다. primitive type이다. 따라서 update는 불가능하고 새로운 객체를 만들기 위해서 rvalue를 본다. rvalue의 값을 보고 새로운 int객체를 만들게 된다. 결론적으로 (1),(2)는 모두 새로운 객체를 생성하고 symbol이 가리키는 모습이다. 그런데, 지금까지 설명한 게 맞는지 안맞는지를 확인할 수는 없을까?
a = 3 print(id(a)) a = a+ 1 print(id(a))a = 3 print(id(a)) a += 1 print(id(a))id()를 사용하면 object의 address를 알수 있다. 그러나 위의 경우는 primitive data type을 a가 가리키기 때문에 매번 새로운 객체를 생성한다. 그래서 다른 id값이 나온다.
참고로 비트 연산자들도 연산자 축약을 사용할 수 있다. 아래는 xor연산자를 보여준다.
a = 7 (1) a = a ^ 4 (2) a ^= 4 -
-
비교 연산자
(1) x < y (2) x > y (3) x <= y (4) x >= y (5) x == y : x,y value가 같다. (6) x is y : x,y 주소가 같다. (7) x != y : x, y value가 다르다. (8) x is not y: x,y 주소가 다르다. (9) x in X : x가 X에 포함된다. (10) x not in X : x가 X에 포함되지 않는다.여기서 기억해야 할것은 (6)과 (7)이다. ==의 경우 python interpreter는 evaluate하는데, 즉 객체의 value를 꺼낸다. 그리고 is의 경우 python interpreter가 꺼내는 것은 객체의 주소다.
primitive 객체들의 value를 꺼내면 3,3.0,True, “abc"와 같은 value가 나온다. 반면 primitive 객체가 아닌것들의 value를 꺼내면 address가 나온다. 따라서 primitive 객체들을 비교하는 경우, (5)를 쓰고, 아닌것들은 (6)을 사용하면 된다. 그런데 primitive data의 evaluate하면 value가 나온다고 했는데, 이 객체의 value들은 address라고 봐도 된다. 왜냐면 primitive data type의 일부 객체들은 객체들은 java에서 처럼 constant pool, string pool과 같은 cache,혹은 string interning방식으로 미리 저장되어 있다. 이 cache의 값들은 unique한 value들은 unique한 address를 갖는다. 따라서 pool에 객체를 저장할때 return되는것은 주소가 아니라 value가 return된다. 어차피 unique하기때문에 상관없다. 3이라는 객체가 pool에 저장될때 return값은 3이다. 주소는 unique한 정보를 담고 있다. value도 unique하다면 주소를 사용하나 value를 사용하나 동일하다. 예를 들어 보자. 값비교에는 == 기호로된 operator가 사용되고, address비교에는 is라는 문자열로된 operator가 사용된다.
x= 3 y=3 print(id(x)) print(id(y)) print(x == y) print(x is y)x = 3을 interpreter가 해석하면, rvalue인 Int 3객체를 constant pool에서 생성한다. 만일 constant pool에 해당 객체가 있다면 그 값만 return할 것이다. 지금은 pool에 없기때문에 pool에 생성한다. 그리고 생성된 객체를 constant pool에 넣고 주소를 return받는다. 그러면 x:주소를 symbol table에 저장한다. constant pool에서는 주소와 value가 unique하기때문에 주소나 값이나 동일하다. 그리고 y=3을 실행한다. interpreter는 Int객체 3을 생성하고, constant pool에 저장할려고 한다. 근데 constant pool에 이미 있기 때문에 pool에 있는 주소를 return한다. 주소와 값이 같기 때문에 값을 그대로 return하고 symbol table에 y:3을 저장한다. 따라서 id()로 본 주소는 동일한 값이다. value도 물론 동일하다. 이제 또 다른 예로, list객체를 보자. primitive data type 객체가 아니다. 이런 객체들은 pool이 아닌 heap에 저장된다.
a = [1,2] b = [1,2] print(id(a)) print(id(b)) print(a == b) print(a is b)4349596928 4349697536 True Falseinterpreter는 [1,2]라는 list객체를 생성하고 heap넣는다. heap이나 pool에 저장되면 주소가 return된다. 그리고 symbol table에
-
boolean operator
- operand가 boolean type일때 수행한다. bit operator는 operand가
arithematic이다.
- not
- AND
- OR
- operand가 boolean type일때 수행한다. bit operator는 operand가
arithematic이다.
-
operator priority
- 기본적으로 산술연산자 > bit연산자 > 비교연산자 > 논리연산자의 순이다.
mutable vs immutable
- primitive data type은 값을 변경할 수 없는 immutable이다.
-
example1
-
example
(1) a = 10 (2) b = a (3) a += 1 (4) a, b, a is b- python interpreter는 a = 10을 본다. 우선, lvalue인 a에 대해서 symbol table에서 확인한다. 없다. 그리고 rvalue를 본다. int type이란 것을 알기에 int객체를 만들고, name과 value를 설정한다.
- python interpreter는 b = a를 본다. lvalue인 b가 symbol table에 있는지 확인한다. 없다. rvalue인 a를 본다. symbol table에 있다. 해당 객체의 type정보만 가지고 온다. int다. 이제 객체를 만든다. b라는 이름과 a라는 값을 갖는 객체를 만들었다.
- python interpreter는 a += 1을 본다. lvalue인 a를 symbol table에서 찾는다. a는 10의 값을 가지고 있는 immutable한 객체다. rvalue를 본다. a가 가진 값과 1을 더해 11이란 값을 만든다. 이제 객체를 만들어야 하는데, lvalue가 immutable하기 때문에 update할 수 없다. 새로운 객체를 만든다.a라는 새로운 객체를 만든다. 그러면 기존 a객체가 갱신된다.
- 여기서 확인해야 할 것은 b의 value다. b의 value는 a인것인가? 아니면, a가 가진 값인가? 지금 봤을때는 a가 가진 address인거 같다. 그래서 (3)까지 출력했을 때, a값은 새로운 객체의 11값을 가지고, b의 경우는 옛날 객체인 a의 값인 10을 갖는다. 새로운 a객체를 가르키지 않는다. 그리고 a is b는 false다. is라는 함수는 a와 b의 값을 가져오기 때문이다.
-
-
example2
(1) a = [1,2,3] (2) b = a (3) a += [4] (4) a, b, a is b- python interpreter는 a = [1,2,3]을 본다. lvalue를 보고 symbol table에서 a를 찾는다. a는 없다. rvalue를 본다. [1,2,3]이다. eval할 필요가 없다. 이제 객체를 만든다, name,value를 연결한다.
- python interpreter는 b = a를 본다. lvalue의 b를 symbol table에서 찾는다. 없다. rvalue의 a의 type을 확인한다. list다. list객체를 만들고,이름과 value를 연결한다. 여기서 list객체를 만드는지는 잘 모르겠다.
- python interpreter는 a += [4]를 본다. lvalue인 a를 본다. symbol table에 있다. type을 보니 list다. 즉 mutable하다. rvalue를 본다.a +[4]를 계산하자. a의 value인 [1,2,3]의 append를 사용해서 [4]를 추가한다. [1,2,3,4]의 값이 나왔다. 이제 여기서 객체를 만드는것이 아닌 a객체의 value를 update한다.
- a의 값은 [1,2,3,4]이고, b도 [1,2,3,4]이다. a is b는 True가 된다.
-
example3
a = [1,2,3,4] b = a a = a + [5] a,b, a si b
In-place operator에 대해서
- a +=1과 a= a+1의 차이: assignment와 operator의 차이
-
python에서 모든 것은 객체다. 그리고 모든 function은 어떤 객체의 method다. 그런데, 위에서 봤던 operator들은 method의 모양을 하고 있지 않다. 그럼 operator라는 것은 무엇인가? 본질은 method다. 즉, member method이다. 이것은 여기 에서 확인할 수있다. 이제 a += 1과 a = a+1에 대해 말해보자. a += 1에서 +=는 operator임을 알수 있다. member function, 즉 method라는것은 해당 객체의 값을 변경, update를 한다. 그런데 a 객체는 immutable이다. integer literal이기 때문에 값을 변경하지 못한다. 그래서 새로운 객체를 만들어낸다. 만일 a가 list와 같은 mutable한 객체라면, 그 값은 변경이 될 것이다. 그리고 a = a + 1의 경우는 assignment다. 즉, 새로운 객체를 만들어 내는 것이다.
-
examples
-
example1
a = 10 b = a a += 1 print(a) print(b) print(a is b) -
example2
a = 10 b = a a = a + 1 print(a) print(b) print(a is b) -
example2
a = [1,2,3,4] b = a a += [5] print(a) print(b) print(a is b) -
example2
a = [1,2,3,4] b = a a = a + [5] print(a) print(b) print(a is b)
-
-
== 과 is
-
==는 값을 비교, is는 객체의 이름(주소)를 비교
-
example1
- 아래는 False가 나와야 정답인데, 이상하게 True가 나온다.
a = 13453436 b = 13453436 print (a is b)- 아래는 True가 나온다.
a = 13453436 b = 13453436 print (a == b) -
example2
- 이것도 제대로된 결과가 나오지 않는다. True,True,False,True가
정답이라고 한다. print(b is ’long-long-text’) 이 왜 false가
나오는지 모르겠다.
a = 'text' b = 'long-long-text' print(a is 'text') print(a == 'text') print(b is 'long-long-text') print(b == 'long-long-text')
- 이것도 제대로된 결과가 나오지 않는다. True,True,False,True가
정답이라고 한다. print(b is ’long-long-text’) 이 왜 false가
나오는지 모르겠다.
-
example3
a = True print(a is True) -
example4
a = None print(a is None)
Dynamic typing
- type을 명시하지 않고, assign할 때, rvalue를 보고 type이 정해진다.
implicit type conversion
-
bool -> int -> float -> complex bool type은 int type으로 conversion이 가능하고, int는 float로 conversion이 가능하다.
a = True a = a + 2 print(a) a = a + 1.5 print(a) -
python interpreter가 a = True를 보고, Boolean 객체를 만들고, 객체에 a라는 이름과 True라는 값을 맵핑한다.
-
python이 a = a + 2를 본다. lvalue인 a를 symbol table에서 찾는다. 있다. rvalue를 계산한다. a의 value는 True이고, 2라는 값이 넘어온다. 이때 boolean객체의 overriding된 + method가 True와 2라는 값을 더해서 어떤일을 하는지는 정확히 모르겠다. 여튼 더하면 3이란 값이 계산되고, assign을 적용해서, int객체를 만들고 a의 이름과 3이란 값을 갖게 된다.
-
python interpreter가 a = a + 1.5를 보고 위의 과정과 비슷한 과정을 거치게 된다.
-
example2 형변환이 안된다.
a = 1 a + None a + 'text'
explicit type conversion
- complex를 float로, float를 int로, int를 str로 형변환을 할수 있다. 이것은 강제 형변환을 해야 한다.
- example
a = 12345 float(a) complex(a) str(a) bool(a) - bool의 경우는 none,[],{} 등은 false값을 갖는다.
- 형변환의 또다른 예
print(int(75.75)) print(str(75.75)) print(bool('True')) - 소수점 처리 방식
- 소수점 버림: int(75.75)
- 소수점 반올림: round(75.75), object의 method.
- 소수점 올림: math.ceil
type checking
객체에는 type이라는 항목을 가지고 있어서 built-in function인 type()를 사용해서 객체의 type을 return받을 수 있다.
a = 123
print(type(a))
print(isinstance(a,float))
<class 'int'>
False
123을 interpreter는 문자열을 읽고 cache에서 123이라는 Int객체를 가져온다. 그리고 symbol table에 a:123을 기록한다. type(a)는 interpreter가 a라는 객체를 symbol table에서 꺼내서 객체의 type인 int를 return받는다. isinstance()는 인자로 객체와 type을 받는다. 객체로 받은 a는 int고 type은 float다. 따라서 False값이 나온다.