
[sql] programmers sql high score1
introduction
여기에 쓰는것은 누군가가 나에게 sql좀 알려줘 하면 설명해주는 일종의 pattern이다. 그냥 머리속의 생각이라서 대충 이정도는 머리속에 있고 나머지는 검색해서 현업에서 일했다. 즉 아주 기초중의 기초라는 것이다. 하지만, 머리속에 떠오르는 이런 생각이 없으면 개발이 힘들어진다. 누구나 알고 있겠지만, sql은 set theory에 기반한다. 그리고 logic에 대한 개념도 들어가 있다. 이 두 개념에 익숙하다면 그 개념으로 이해해도 된다. 여튼 내가 알고 있는 개념과 Programmers 문제를 풀면서 설명이 필요한것을 적기로 한다. 여기에서 dbms에 관한 sql은 생략한다. 예를 들면 table을 만든다거나, use db로 db를 사용한다거나 이런것들은 생략한다. from where group by having SOL만 다뤄보기로 한다. 그리고 반드시 알아야 하는 집계함수들과 가장 중요한 join만 정리한다. 왜냐면 내가 아는것은 이것밖에 없다. 나머지는 필요에 따라서 검색할 뿐이다.
기본 select문
select라는 건 말그대로 선택한다는 것이다. 무엇을 선택하는가? table의 column을 선택한다. table로부터 column을 선택해서 table을 만드는것이다. 일종의 함수다. 정의역도 table, 공역도 table. select문에는 실행 순서가 있다. 보통은 이렇게 외운다.
from(join) where group by having SOL[select(distint),order by, limit]
좀 유치하긴 해도, 이게 기본 실행 순서이고 각각의 keyword는 모든 select문의 기초이기 때문이다.
from
이제 정의역에 해당하는 table을 기술해보자. 정의역 table을 기술하는 것은 from이다. 왠지 적절한 단어같다. 정의역 table로 부터 원하는 column을 가져와서 table을 만드는 것은 다음과 같다.
select a,b from Atable
이것은 이렇게 해석한다. db에 있는 Atable을 가져온다. 그리고 a,b column data를 꺼낸다. 이렇게 해석하는 이유는 from이 가장먼저 실행되기 때문이다. 의외로 이것을 모르는 사람이 많이 있어서 적는다.
where
table에서 a,b컬럼을 가져온다는 것은 data를 포함한 column을 다 가져온다는 것이다. 여기서 특정 조건의 row data만을 가져올 수 있다. 예를 들어보자.
select district from local where district="busan"
where절의 형태를 보자. 선택된 column district의 row를 제한하기위해서
busan과 같다는 조건을 걸었다. 선택된 column이 일종의 변수와 같은
역할을 한다. 이것도 local이라는 table을 db에서 꺼낸다. 그 다음
district가 busan인것만 추린 table에서 district column만 선택해서 꺼낸
table을 return한다. 순서는 다음과 같다. from => where => select.
like
where에서 조건을 나타낼때 수치로 조건을 나타낼 때와 문자열로 조건을 나타낼 때가 있다. 여기서 다른 연산자가 사용된다. 예를 들어서, a == 30 이거나, a like ‘bread’ 처럼 조건을 표시할 수 있다.
group by
group by는 특정 column의 row data를 group별로 묶는다. 왜 묶을까? 보통은 집계함수(mma cs)를 사용하려고 묶는다. row를 group으로 묶는다는것을 생각해봐라. 예를 들어 sex라는 column을 group으로 묶으면 어떻게 될까? male 아니면 female이다. 두개밖에 없다. 만일 region이라는 지역으로 group by를 하면 지역별로 하나씩만 나오게 된다. 즉 row data를 summary한 느낌이다. 대표값만을 뽑은 느낌이다. 이렇게 하는 이유는 개개의 row data를 사용하지 않고, mma cs라는 집계함수를 사용하기 위함이다. 이것을 명령어의 동작으로 이해하기 보단, mma cs라는 집계함수를 사용하기 위해선 group by를 사용해야 한다는 관점에서 바라봐야 한다. sex라는 항목을 본다면, 남자는 몇명인가? 키가 180이상인 여자는 몇명인가? 남자의 평균 몸무게는? 가장 몸무게가 많이 나가는 남자는? 이런 질문에 답을 하기 위해선 group by를 사용하는 것이다. 그럼 이제 group by를 어떻게 사용하는지 확인해 보자.
이런 table이 있다고 하자.

Figure 1: table
위와 같은 table이 있을때, 다음과 같은 명령을 내린다면 어떻게 될까?
SELECT Country
FROM Customers
group by Country
수행과정을 보자. Customers라는 table을 db에서 가져온다. group by country는 Coutry라는 필드의 data를 대상으로 grouping한다. 즉 대표값만 남는다. 그래서 21개의 row가 있다. 여기서 select Country하면 대표값만 남은 Coutry column만 있는 table을 return한다.
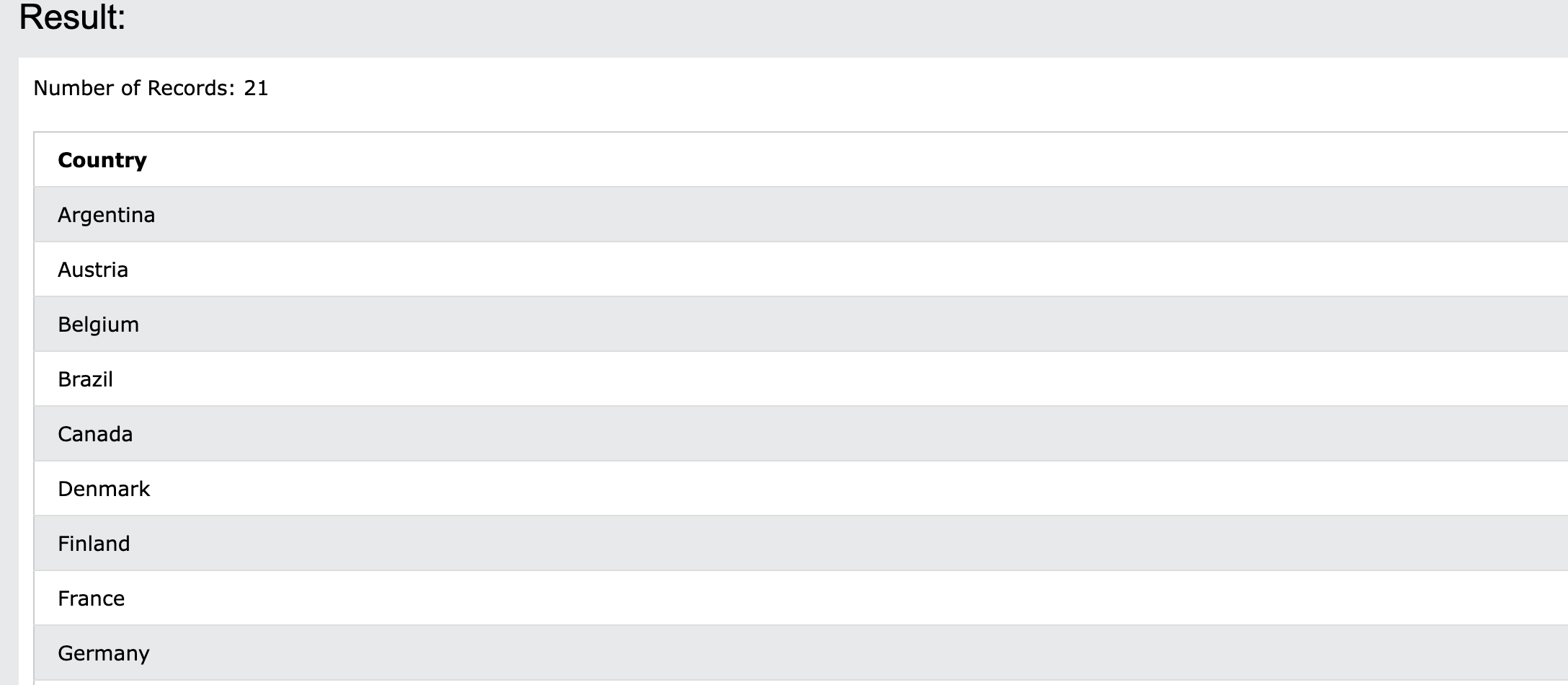
Figure 2: groupby1
이것은 기존에 있던 table의 row에서 대표값만을 가져온다고 했다. 그래서 21개의 row만 가져온다. 원래 table에 Germany라는 값을 갖는 row는 여러개 있지만 하나만 남게된다.

Figure 3: groupby2
그럼 다음과 같은 명령은 어떻게 될까?
SELECT *
FROM Customers
group by Country
Customers table을 db에서 가져온다. group by Country를 실행하면, Country의 대표값만 남는다. 이 상태에서 select *를 하면 아래와 같은 결과를 갖는다.
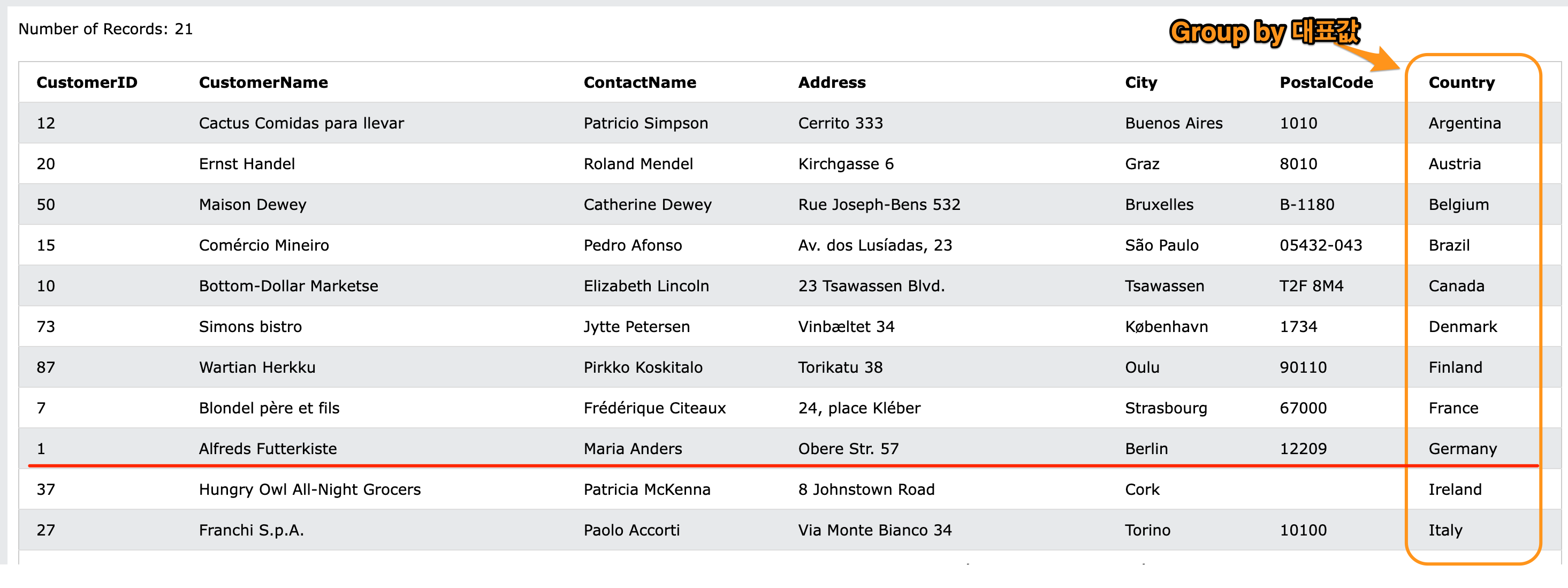
Figure 4: groupby3
여기서 group by로 대표값만 남게 한 상태에서 select *로 모든 column을 가져온다. 여기서 한가지 궁금한 점이 생긴다. 그림에서도 표시했지만, Germany의 경우 Germany값을 갖는 row가 한개가 아니다. 그러면 어떤 row를 가져와 표시하는가? 하는 질문을 할 수 있다. 답은 제일 첫번째 위치의 row를 가져온다. 그리고 결과를 보면 Country대표값의 개수만큼 row가 있다는 것도 알 수 있다. 그런데 group by를 사용하는 것은 단순히 group by를 select distinct Country처럼 사용할려는게 아니다. group by는 group으로 모은 대표값들의 개수라던가, 합이라던가, min,max,average를 알고 싶을때 사용한다. 특정 목적이 있다. 그런 예를 보자.
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;
customer table을 db에서 가져오고 Country로 grouping을 했다. 그러면 country column의 row들은 대표값만 갖게 된다. 여기서 select문의 해석이 달라진다. 집계함수가 사용되기 때문이다. GroupBy로 기준이되는 column값이 정해졌다. 여기서 count(column)이 사용되는데, 즉 기준값에 해당하는 group이 가지고 있는 rows에 대해서 계산을 하는것이다. 위에서는 count(customerid)로 되어 있기 때문에, 각각의 대표값에 해당하는 group이 가지고 있는 row들에 대한 개수값을 계산한다. 만일 Max(CustomerID)로 하면 각 group이 가지고 있는 row중에 최대 id값을 return하게 되는 것이다. average도 마찬가지다. select문에 집계함수 옆의 Country는 그냥 알아보기 좋게 하려고 추가한 것이다. 결과는 다음과 같다.
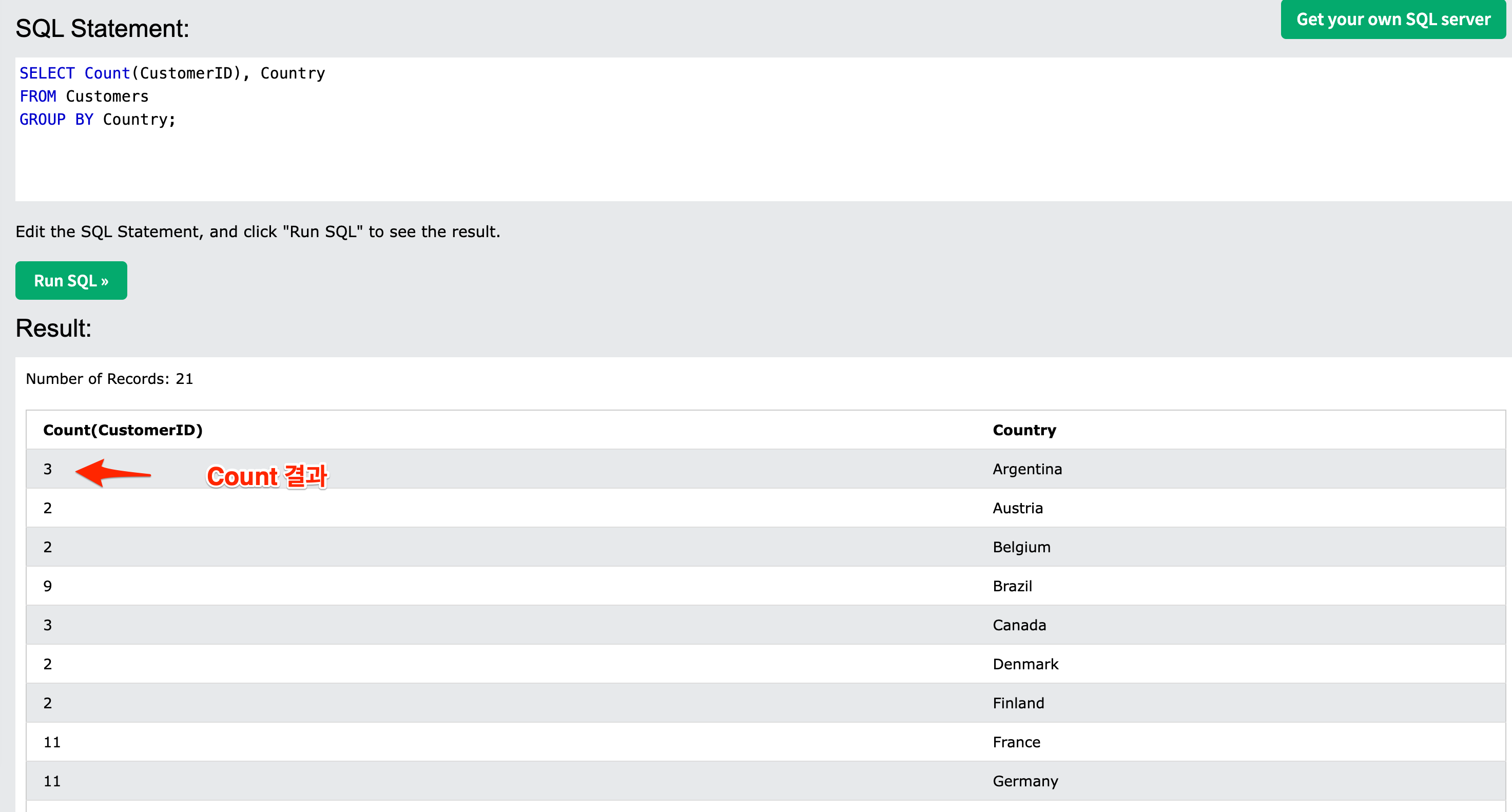
Figure 5: count
max에 대한 처리 결과도 다음과 같다.
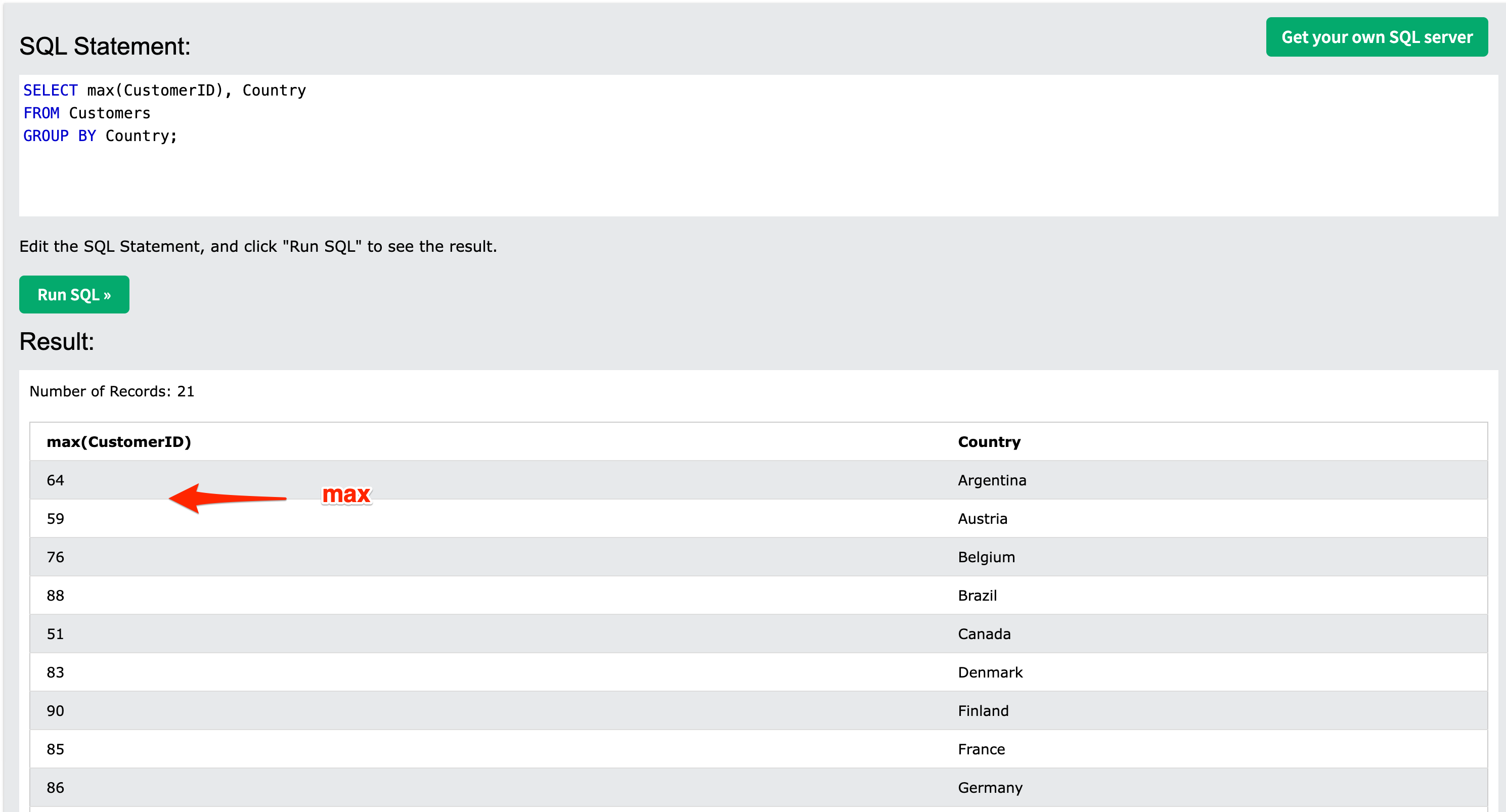
Figure 6: max
avg에 대한 처리 결과는 다음과 같다.
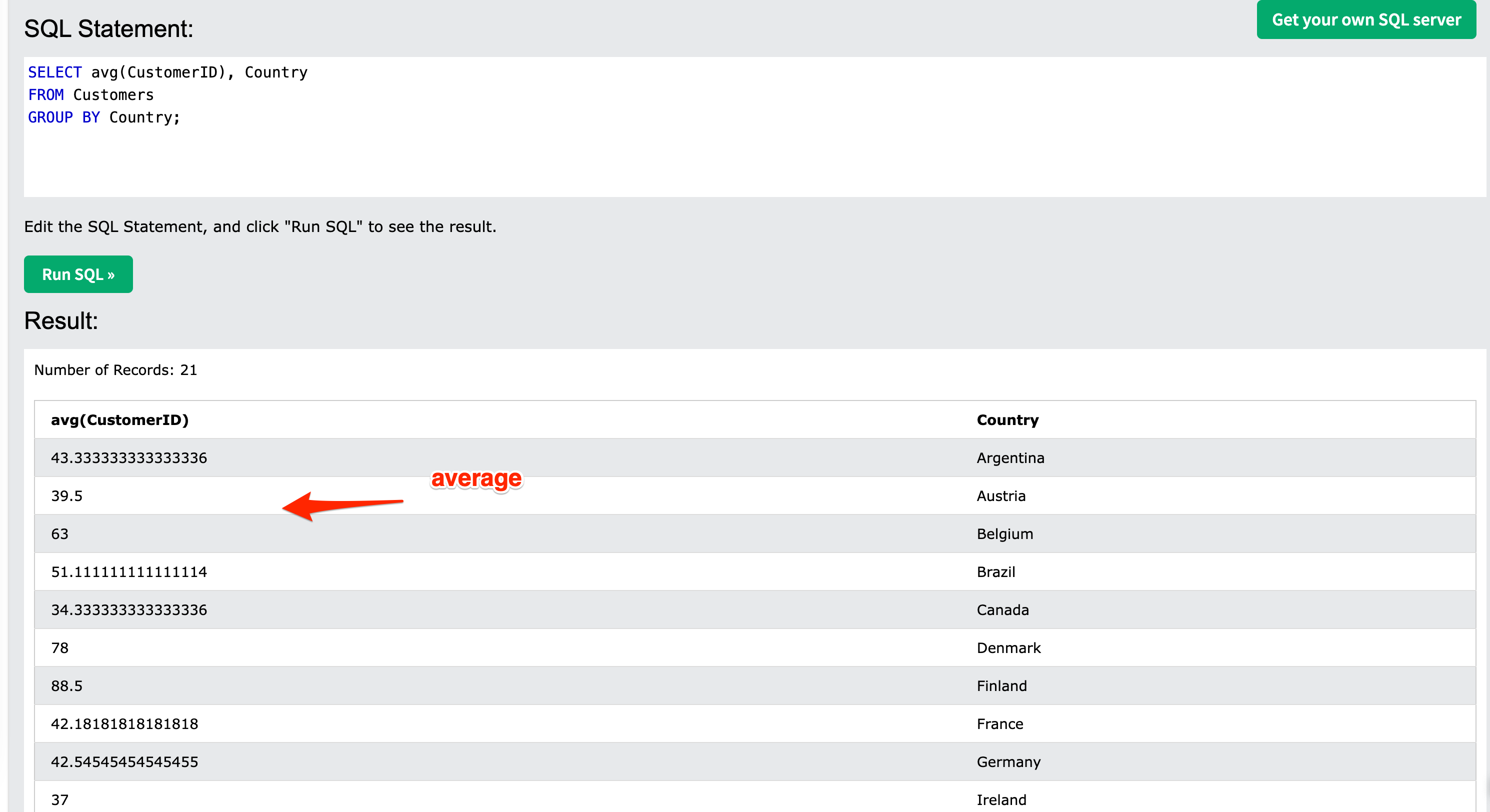
Figure 7: avg
내가 알고 있는 group by는 이게 전부다.
group by에 대한 좋은 예
위에 있는 예는 좀 보기 어렵다. group by로 group화하고 집계함수 쓰는게 있어서 web에서 긁어왔다. 출처는 다음과 같다. 여기
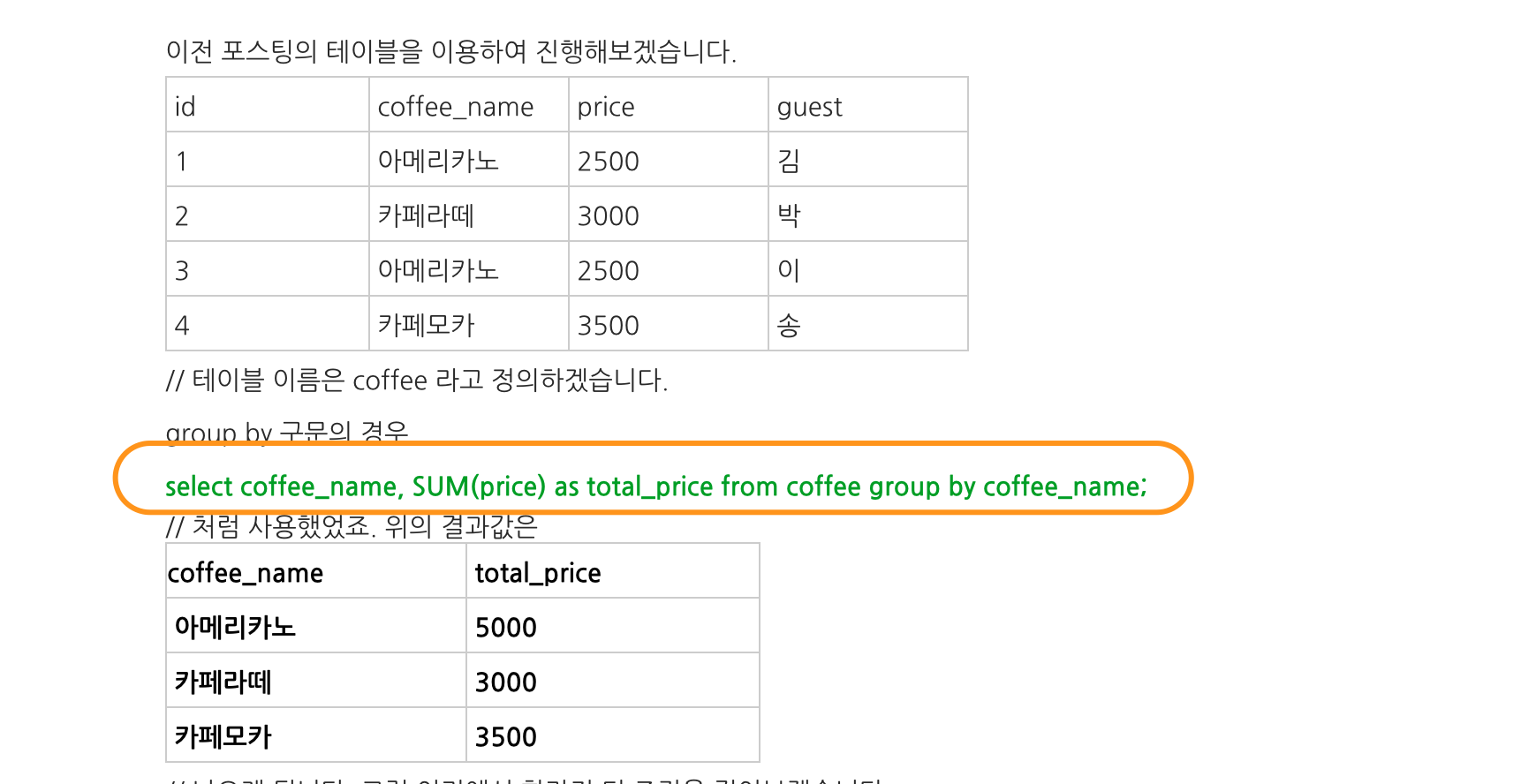
Figure 8: example1
having
having은 group by에 포함되는 건데, 외울때 group by having SOL로 외워서
별도로 해놓았다. 다른곳에선 group by로 group을 만든 후에 having으로
조건을 건다고 한다. 그런데 내가 봤을때 보통 having으로 조건을 걸고
group by로 grouping하는 순서가 아닐까 한다. 여튼 그렇다. sql문
작성순서는 group by다음에 위치한다. 다시한번 말하면 나는 having절은 group by를 하기전에 먼저 조건을 거는 것 이라고 생각한다. 조건을 걸때
보통 집계함수를 사용해서 제한을 건다. 위에서 좋은예로 설명한 곳에서
having도 같이 설명했기때문에 붙여넣는다.

Figure 9: example2
sql을 해석하면 다음과 같다. coffee라는 table을 db에서 가져온다. group으로 묶기 전에 having을 먼저 처리한다. 즉 coffee name이 하나 이상인걸로 조건을 걸어버린다. 그러면 아메리카노 밖에 없다. 여기서 group by를 하면 아메리카노밖에 없다.
select
개요
select는 출력할 column을 최종적으로 선택하고 선택된 column의 각 row 데이터를 가공할 수 있다. if문을 사용해서 특정 row data는 출력하지 않는다던가, distinct로 중복되지 않는 데이터만 출력하던가, 집계함수를 적용해서 출력한다던지, 여기서 최종 data를 manipulation한다.
distinct
distinct는 중복을 피하는 keyword다. select절에 포함된다. select절을 수행할 때 실행되는데, 굉장히 많이 쓰이는 편이다. 예를 들면,
select distinct people_id from Atable where city='인천'
이런 식으로 사용된다. 이것이 의미하는 것은 Atable을 db에서 가져온다. city가 인천인 table을 만든다. 이런 table에서 peple_ID가 중복되지 않은 column을 꺼내서 return한다. select distinct가 하나의 절이다.
집계함수
mma cs로 외우자. min,max,average 그리고 count, sum이다. 가장 많이 쓰이는 집계함수다.
order by
order by는 내림차순에 해당하는 desc, 오름차순에 해당하는 asc가 있다. 내림차순이라는건 row의 order(순서)가 내려갈수록 값이 낮아지는것이고 오름차순은 row의 order(순서)가 내려갈 수록 값이 커지는 것을 말한다. 사용법은 단순하다.
order by col1 desc, col2 asc
이런 식으로 추가하면 된다. 해석은 col1의 값으로 내림차순으로 정렬한다. 만일 col1의 값이 같다면 col2의 값으로 오름차순으로 정렬한다.
from으로 table을 가져오고 where로 row를 제한하고, 여기서 having과 groupby로 group화해서 table을 만든다. 여기에 select로 원하는 table을 return하기 위해서 column을 선택한다. 그런 다음에, order by로 정렬을 한다. order by는 너무 단순해서 예를 들진 않겠다. 다만 숫자가 사용될 수 있음에 유의하자. order by 1,2는 select col1, col2, col3일때 col1 과 col2를 의미한다.
limit
limit은 최종 return할 table이 만들어졌을 때, row수를 제한한다. 사용법은 다음과 같다.
limit 시작점, 개수
limit 2,1
limit 2,1은 3번째 row의 row 1개만 보여준다.
요약
이것이 기본적인 select문의 구조다.
join 개념들
상식적으로 join을 보자.
하나의 table에서 column을 선택해서 table을 만드는게 아니라, 2개의 table에서 column을 뽑아내서 만들 수는 없나? 그럴려면 2개의 table을 기술해야 한다. 예를 들어서,
select a,b from Atable, Btable
위와 같은 형태로 기술할 수 있다. 근데 a와 b는 Atable의 column인가? 아니면 Btable의 column인가? a,b라는 column은 Atable에도 Btable에도 있을 수 있다. 따라서 이런 표기법은 문제가 있다. 다음 표기법은 어떤가?
select Atable.a,Btable.b from Atable, Btable
일견 그럴싸하다. a라는 column은 Atable에서 선택한다는 명확한 의미전달이 가능하기 때문이다. 하지만 이렇게 사용하진 않는다. join이라는 keyword를 사용해서 표현한다.
select Atable.a,Btable.b from Atable join Btable
그럼 다음과 같은 상황을 살펴보자.
select SeoulElementarySchoolTeachers.a, BusanPeopleTable.b from SeoulElementarySchoolTeachers join BusanPeopleTable
뭔가 불편하지 않은가? 그렇다. 이름이 너무 길다. sql에선 as를 제공한다. table 이름이나 column name이 길때는 as를 사용한다.
as 사용법
as 사용법은 다음과 같다. 컬럼의 경우, select에서 as를 사용한다.
SELECT column_name AS alias_name
FROM table_name;
table의 경우, from에서 as를 사용한다.
SELECT column_name(s)
FROM table_name AS alias_name;
이것에 맞추어 다시 수정해보자.
select SeoulElementarySchoolTeachers.a, BusanPeopleTable.b from SeoulElementarySchoolTeachers join BusanPeopleTable
table명만 길기 때문에 from에서 바꿔주면 된다.
select Seoul.a, Busan.a from SeoulElementarySchoolTeachesr as Seoul join BusanPeopleTable as Busan
위에서 join을 마치 아무 table을 2개 연결해서 하나의 table을 만들어서 사용하듯이 얘기했지만, 실은 원래 하나인 table을 여러개로 쪼갠 후에 연결해서 사용하는 것이다. 즉 원래 table을 쪼개서 여러개의 table로 만드는 것이 시간상 위에 위치하게 된다. 이것은 정규화와 관련된 얘기라서 나중에 join을 구체적으로 다시 설명할때 얘기 하기로 하자.
join의 적용
위에서 설명을 했지만, join이라는게 아무 table이나 합쳐서 새로운 table을 만드는 것이 아니다.
select Seoul.a, Busan.b from SeoulElementarySchoolTeachesr as Seoul join BusanPeopleTable as Busan
join이라는게 2개의 table을 연결해서 하나로 만든다고 했는데, 상식적으로 아무 관계도 없는 2개의 table을 하나로 합친다는게 말이 안된다. 물론 아무 관계도 없는 A라는 table에 B라는 table의 column들을 그냥 떼다가 A에 붙일수는 있다. sql의 join을 사용해서 붙이도록 동작 시킬수 있다. 붙여지게 된다. 하지만 이게 제대로된 table일까? A라는 table은 고객에 대한 정보를 갖는 table이라고 하자. B는 쇼핑아이템에 대한 정보라고 하자. 그냥 두개의 table을 합쳤다면 사람에 대한 정보와 쇼핑아이템에 대한 정보가 아무런 연관도 없는데 그냥 연결해 버린 것이다. 이렇게 아무 관련 없는 table을 합치게 하게 위해서 join이라는게 나온건 아니다. 위에서도 말했듯이 한개의 table을 이미 이전에 쪼개 놓았다. 이 전제를 잊으면 안된다.
ON의 사용
-
on의 사용법
그래서 On이라는게 사용된다. On은 2개의 table을 연결하는 공통적인 접점(column)을 의미한다. 사용법은 다음과 같다.
select A.process_id, B.date, B.name from A inner join B on A.id = B.id다른 것보다 같은 컬럼을 합치는 부분을 보면된다.
on A.id = B.id
-
foreign key에 대해서
on을 설명하기 위해선 foreign key와 primary key라는 용어가 등장한다. 알아둘 필요가 있어서 생각나는대로 쓴다. 여기서 A table의 id는 primary key이고 B table의 id는 foreign key이거나 하다. db를 배운사람들은 알겠지만, table에 primary key가 있는 것은 당연하다. 모든 table에는 primary key가 있어야 하기 때문이다. 그런데 다른 table의 primary key인 foreign key column으로 들어와 있는 경우는 일반적이진 않다. foreign key가 들어있다는 것은 foreign key를 primary key로 사용하는 table과 원래 하나의 table이였으나 중복문제로 별도의 table로 떼어냈다고 보기 때문이다. 즉, 정규화 과정을 거친것이다. 이렇게 별도의 table로 떼어내면, 별도의 table에선 중복을 하지 않게 처리한다. 그리고 원래의 table은 foreign key로 참조하기 때문에 중복되지 않은 data를 참조하는 것이다. 이것에 대한 설명을 할려고 하는데, 막 한달전 쯤 생활코딩이라는 데에서 sql join에 대한 별도의 강의를 만들었고 여기서 그것을 설명한다. 좋은 설명이다. 내가 할려던 설명이였다. 참조 , 나는 강의를 다 보지는 않았지만, 영상에선 제2 정규화를 얘기하는 것 같다. db에서 table을 design할 때, 가장 먼저 하는건 table설계다. table 설계할 때, 큰 뭉텅이로 table을 만든다. 일종의 객체의 모든 정보를 table과 mapping하는 것이다. 학생이면 학생이란 객체의 모든 속성값을 학생 table의 column으로 때려박는다. 하지만 이렇게 table에 여러개의 column을 사용하면 반드시 중복되는 데이터가 생기게 된다. 그래서 정규화를 한다. data값이 여러개이면 하나의 값을 갖도록하는 1정규화도 있고 column을 자르는 2정규화도 있다. 5정규화까지 아마 있을 것이다. 여튼 학생이란 속성을 학생이란 table에 박아넣으면 30개의 column을 가진 table을 만들수 있을 것이다. 이렇게 하면 중복되는 column data도 문제지만, query하면 속도도 느려진다. 그러나 요즘은 워낙 기술이 발달해서 이정도로는 체감될 정도는 아니다. 하지만 data의 양이 늘어나면 속도저하가 필연적이다. 그러면 table을 무조건 쪼개는게 능사일까? 그렇지는 않다. 장단점이 있기 때문이다. 장점은 program에서 사용하기 편하다. 코딩하기 편한것이다. 그냥 table의 학생 data를 꺼내서 학생 객체에 매핑만 하면 된다. query가 간단해진다. 예를 들어서 select * from student where student_id =1; 과 같이 사용하면 된다. table을 쪼개개 되면, 학생 id가 1인 데이터를 꺼내기 위해선 join을 통해서 다시 하나의 table로 만드는 과정이 필요하다. 즉 sql이 복잡해진다. 레고블럭처럼 table을 작은 단위로 하면, 자유도는 증가한다. 예를들어 원래 학생 table을 여러개로 쪼갠 상태에서 내가 원하는 table이 학생의 모든 정보가 아닌, 학생이 속한 학교와 학생 개인정보라면 2개의 table만 join해서 하나의 table을 만들수 있기 때문이다. programmer가 개입하는 자유도와 만들수 있는 학생 data도 많이 늘어난다. 그리고 중복 문제도 없애고 여러모로 좋다. 다만 programmer의 table 설계능력과 조합능력을 필요로 한다는 것이다. 즉 coding이 어려워진다. 여튼 아는대로 씨부려 봤다.ㅎㅎ 다시 한번 정리하면 여기서 primary key와 foreign key가 등장하는 이유를 설명했다. 즉 원래 한 table을 쪼갯기 때문에 foreign key가 필요한 것이다.
-
on과 join
위에서도 말했듯이 join은 이미 쪼개진 table을 조합해서 새로운 table을 만드는 것이다. 여기서 on은 조건인데 이 조건에 따라 만들어지는 table이 달라진다.라고 어떤 책에서 얘기하는데, 그렇지는 않다. join 종류에 따라 만들어지는 table이 달라지는 것이다. on은 모든 join에서 공통적이라고 보면 된다.
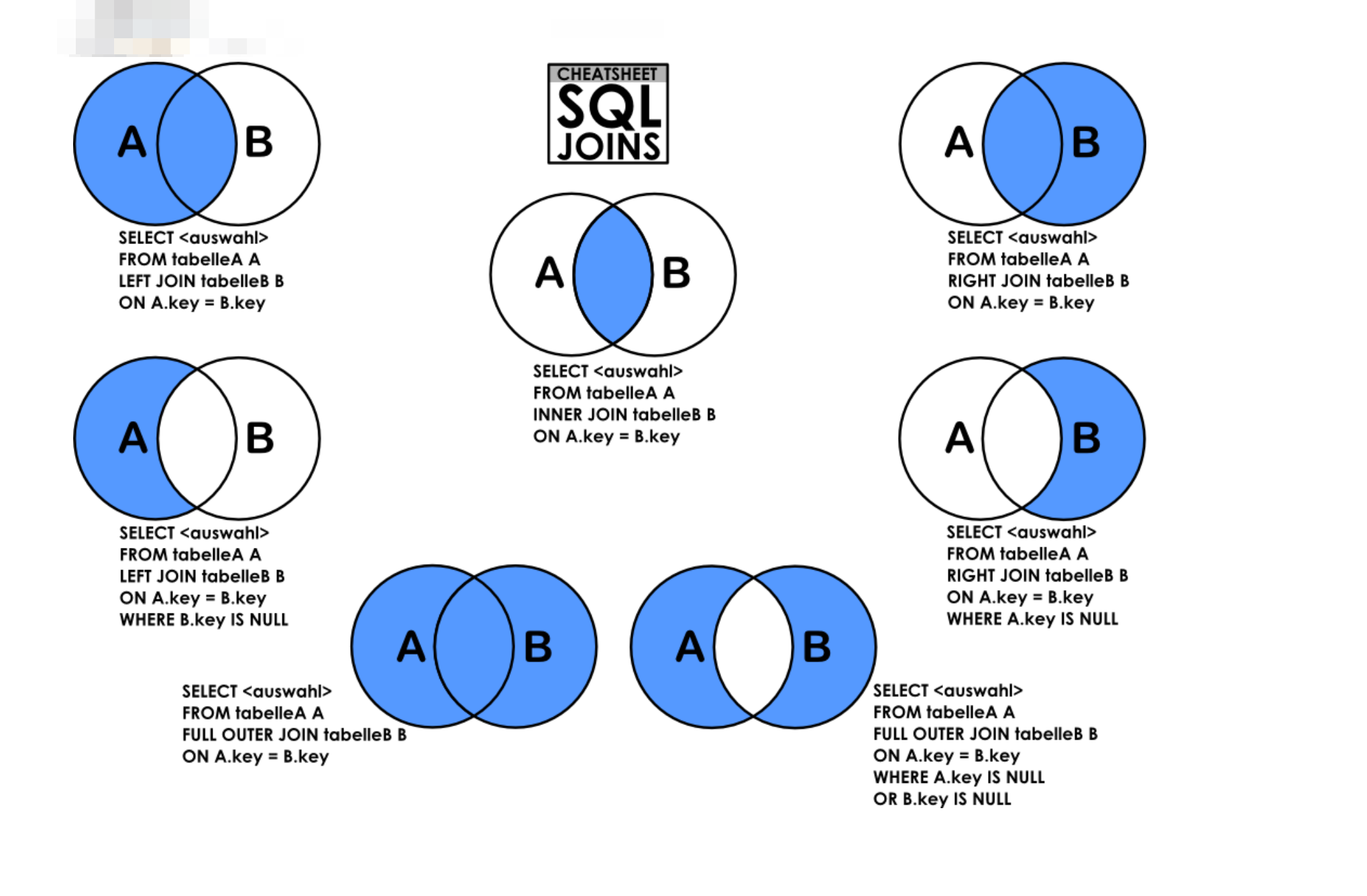
Figure 10: join
이 그림들에 대한 설명을 이제 설명할 것이다.
inner join (default)
outer join
lefter join
right join
subquery
요약
query문을 작성하는 순서